RAG Chatbot
In this example, we’ll build a basic RAG chatbot. The chatbot will be able to answer questions whose answers are grounded in the contents of PDF documents (in this case, Vellum’s Trust Center Policies). This is useful if you want to help scale your support team by finding them quick answers to common questions from customers.
Ultimately, we’ll end up with a Workflow that performs the following steps:
ExtractUserMessage: extracts the most recent message from the userSearchNode: uses the user’s message to find relevant quotes from ingested PDFsFormatSearchResultsNode: reformats quotes to include the name of the document that they came fromPromptNode: passes the user’s question and the PDF context to the LLM to answer the question
Which corresponds to a Workflow graph like this:
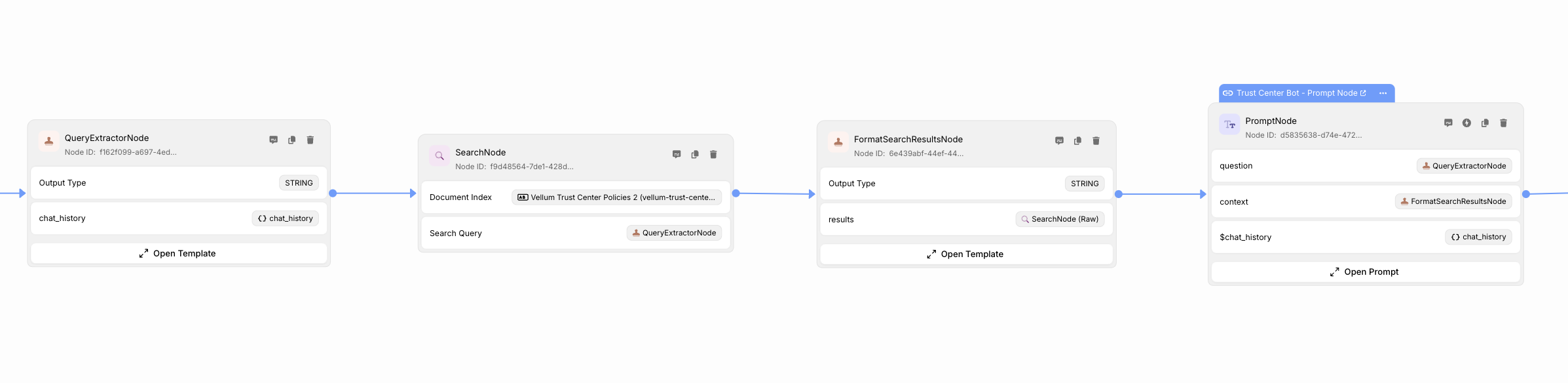
Let’s dive in!
Setup
Install Vellum
Create your Project
In this example, we’ll structure our project like this:
Folder structure matters! Vellum relies on this structure to convert between UI and code representations of the graph. If you don’t want to use the UI, you can use whatever folder structure you’d like.
Define Workflow Inputs
Our chatbot will have a chat history, which is a full list of messages between the user and the bot. If we want, we could use this to answer follow-up questions with context from previous messages.
Build the Nodes
Extract User Message
We’ll use the output from this node in the next step— to search relevant documents to answer the user’s question factually.
You can see that we’re subclassing the TemplatingNode class, which allows us to use a Jinja template to extract the user’s query from the chat history.
Search Node
Specify which document index to search over, and use the user’s query to find relevant chunks of information.
Here, we subclass BaseSearchNode, which allows us to specify a document index to search over, and a query to search with. Vellum provides out-of-the-box, scalable vector database and embeddings solutions that make this easy.
Format Search Results Node
This is an optional step, but it can be useful to format the search results in a way that’s optimal for an LLM to consume. You may want to include metadata in a certain format or omit it altogether. Here, we include the name of the document that each chunk came from, so that we can later instruct an LLM to cite its sources.
Instantiate the Graph and Invoke it
Running the Workflow
Using the Sandbox Runner
The sandbox runner is ideal for testing and development. It enables you to execute the workflow locally using sample inputs, providing a quick way to validate functionality.
You can run the sandbox runner by running the following command: python -m basic_rag_chatbot.sandbox 0 (where 0 is the index of the Scenario you want to run).
Conclusion
In under 120 lines of code, we built a RAG chatbot that can answer users’ questions with context from a vector database. Looking forward, we can:
- Version control the graph with the rest of our project in a git repository
- Continue building the graph in the Vellum UI
- Evaluate the pipeline with test data, see Evaluating RAG Pipelines
- Host it on our own servers or deploy to Vellum