Evaluating RAG Pipelines
Retrieval Augmented Generation (RAG) is a powerful technique to improve your LLM output quality by providing it relevant data - usually retrieved from an external knowledgebase.
In Vellum, setting up your RAG pipeline is straightforward using our Documents feature. Upload and vectorize your knowledgebase for use in minutes. For more details on how to set up a RAG pipeline in Vellum, see common architectures here.
Once you have your RAG workflow set up, a challenging but important and often overlooked aspect is evaluating quality. When it comes to RAG, you’re not only interested in the quality of your LLM response (the Generation), but also the context being returned from your vector database (the Retrieval).
Essentially, you’re checking to see how effectively your system retrieves relevant information from a knowledge base and then uses it to produce reliable and precise responses or content.
RAG evaluation is a continuous process - running these evaluations gives confidence when initially deploying your RAG into production but the benefits continue post-deployment. Running these evals in production help you understand your system’s current performance and identify areas for optimization.
Using Out-of-Box RAG Metrics in Test Suites, Vellum makes it easy to evaluate, monitor, and continuously improve your RAG pipeline over time without concern of introducing regressions.
Read on to see how you can evaluate your RAG pipeline in Vellum!
RAG Evaluation in Vellum
Set up your RAG pipeline for Evaluation
- Step 1: Create a Document Index and upload your documents (follow this article for tips: Uploading Documents)
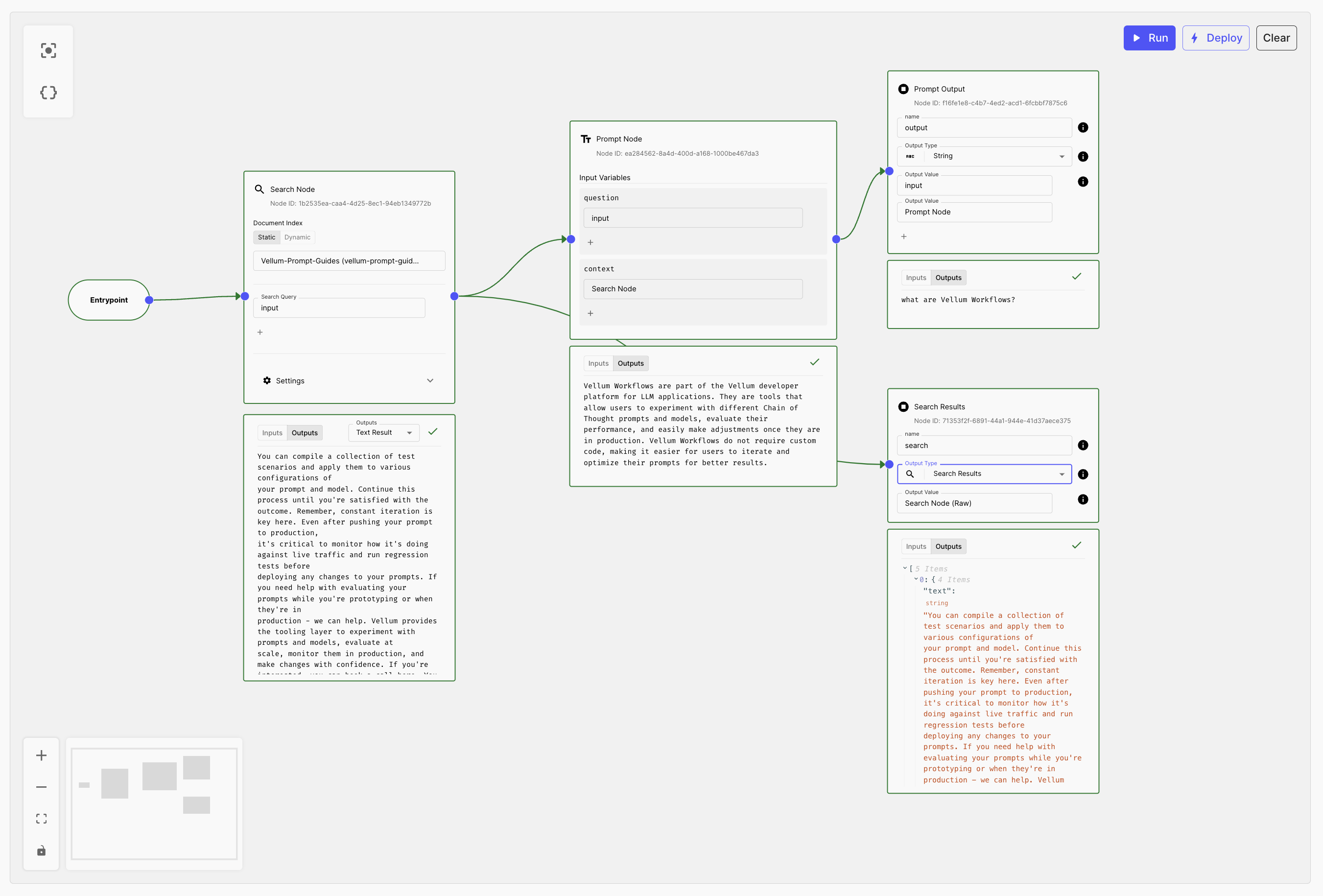
- Step 2: Add a Search Node in your Workflow
- Step 3: Add a Prompt Node that takes the results of your Search Node as an input variable
- Step 4: Link the output of the Prompt Node to a Final Output Node (for evaluating Generation)
- Step 5: Link the output of the Search Node to a Final Output Node (for evaluating Retrieval)
- Step 5: Set up your Workflow variables and hit Run!
Once your RAG pipeline runs and passes visual inspection, it’s time to set up your Test Suite.
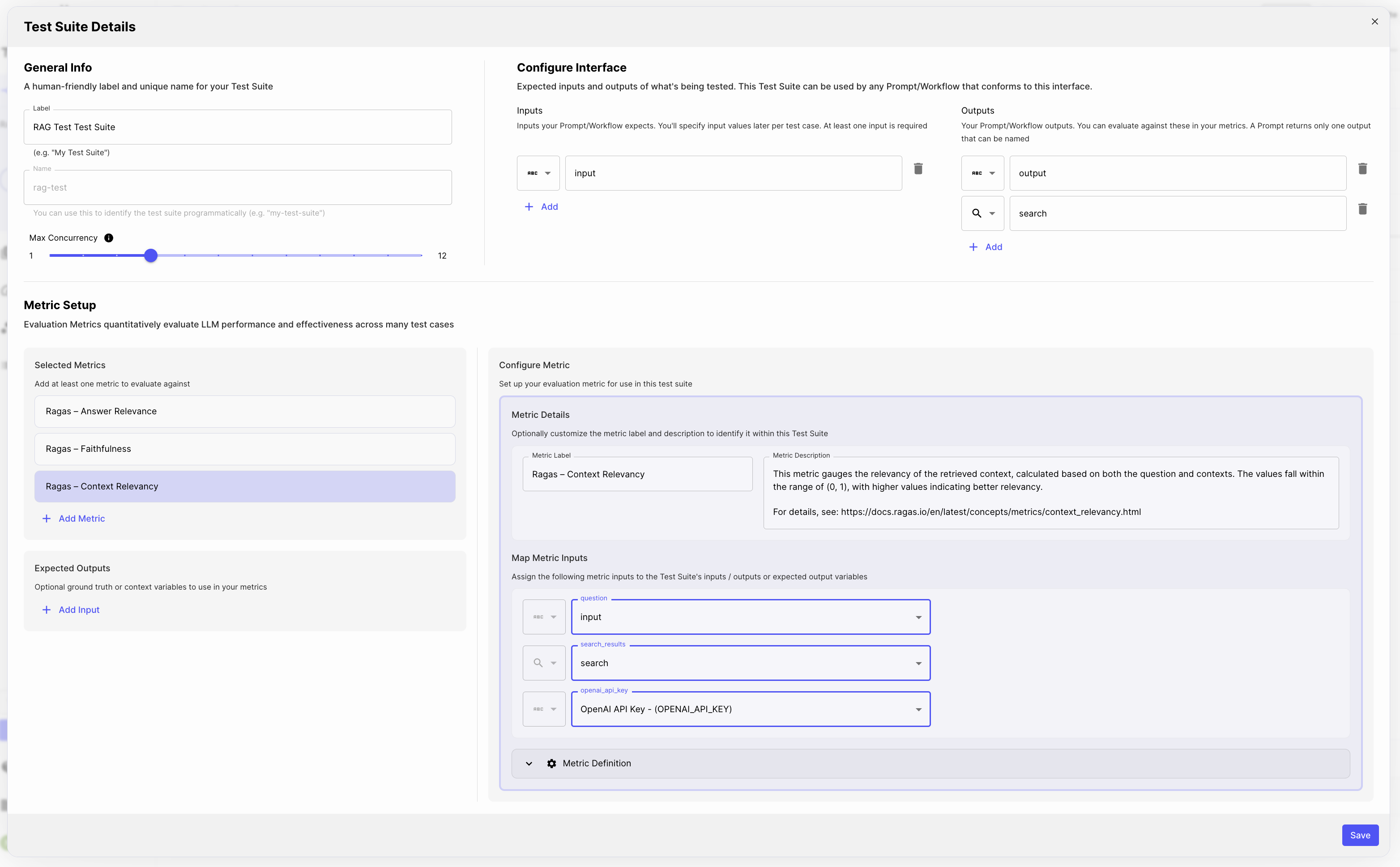
Set up your Test Suite
- Step 1: Create a Test Suite for this Workflow (follow this article for more info: Quantitatively Evaluating Outputs
- Step 2: Add the following Ragas Metrics: Ragas - Faithfulness, Ragas - Answer Relevance, Ragas - Context Relevancy
- Step 3: Map the Test Suite variables to the Metric Inputs
- Step 4: Add your Test Cases and hit Run!
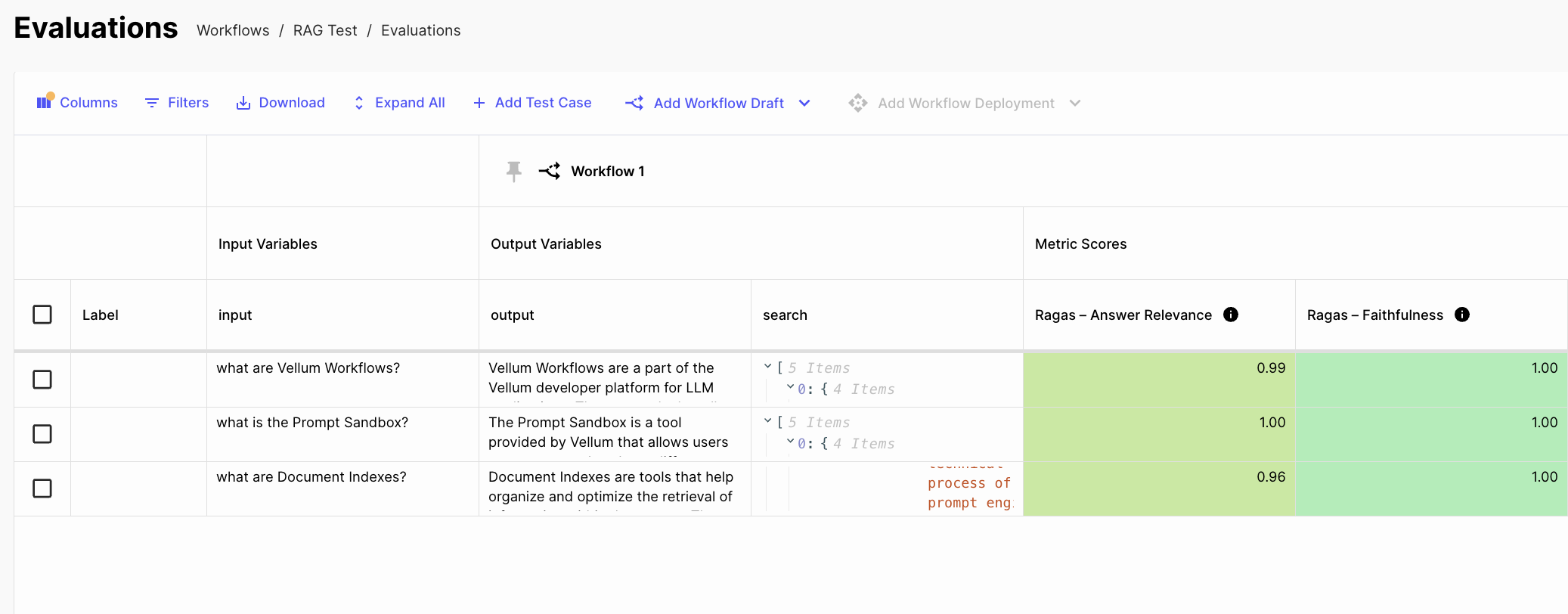
Now you can see how well your RAG pipeline performs across a bank of test cases!
Depending on your results, you can adjust the appropriate component in your RAG system.
Generation
Answer Relevance and Faithfulness are Generation evals that measure the quality of the LLM response and guard against hallucinations.
If you see low performance here, you can optimize your Prompt.
Try adjusting the Prompt itself, tweak Model parameters, or try a different Model for better performance.
Read more about Prompt Engineering best practices from the Vellum team:
Retrieval
Context Relevancy is a Retrieval eval. If you see low performance here, you can optimize your Document Indexes.
Try different embedding strategies, chunking sizes, and add metadata filtering so the context returned is precise and relevant to the question being asked.
If these methods don’t improve performance enough, make sure the documents you’ve uploaded are clean from any noise or extraneous elements that can negatively impact their vector representation and your results.
This includes:
- Header / footer info
- Extra or special characters
- New Lines
- Inconsistent formatting (including capitalizations)
Once the documents are processed, you can also try more sophisticated Workflow methods such as splitting your knowledge base into separate Document Indexes and dynamically selecting the right Document Index to use in your Search Node. This method often involves an additional LLM call from a simpler model (think GPT-3.5 turbo) that is used to categorize and select the correct Document Index base on the question being asked.
To learn more about Retrieval Augmented Generation and the most effective Metrics to use in your RAG pipelines, check out our blog article