Changelog | May, 2024
Changelog | May, 2024
Context Menu for Workflow Edges and Nodes
May 31th, 2024
You can now right-click on Workflow Edges to open a context menu to allow you to delete them without having to hunt down the trash icon. You can also now right-click on Workflow Nodes to delete them as well.

Breadcrumbs and Page Header Improvements
May 31th, 2024
We’ve significantly improved folder and page breadcrumbs throughout the app. Prompts, Test Suites, Workflows, and Documents now display the entire folder path of your current page, making it much easier to navigate through your folder structure. We’ve also updated the overflow styling for breadcrumbs: instead of an ellipsis, you’ll now see a count of hidden breadcrumbs, which can be accessed via a dropdown menu.
Additionally, the pages mentioned above, along with Workflow/Prompt Evaluations and Deployments, now feature the same updated header design.

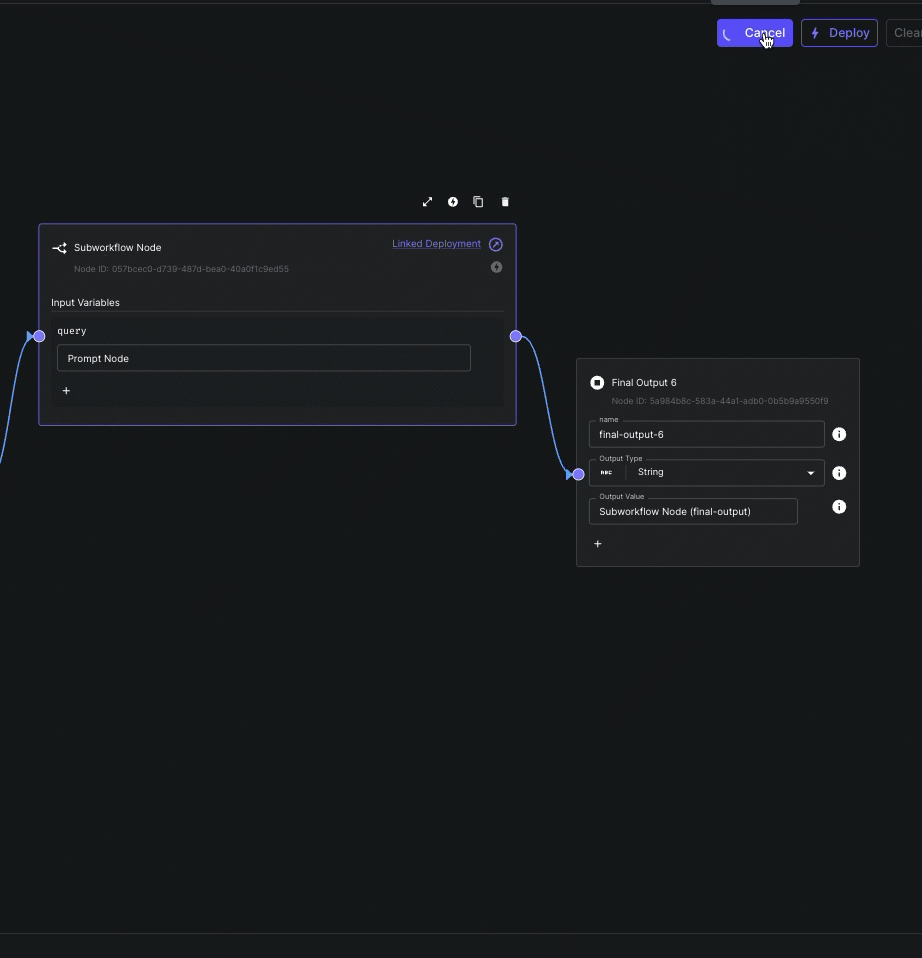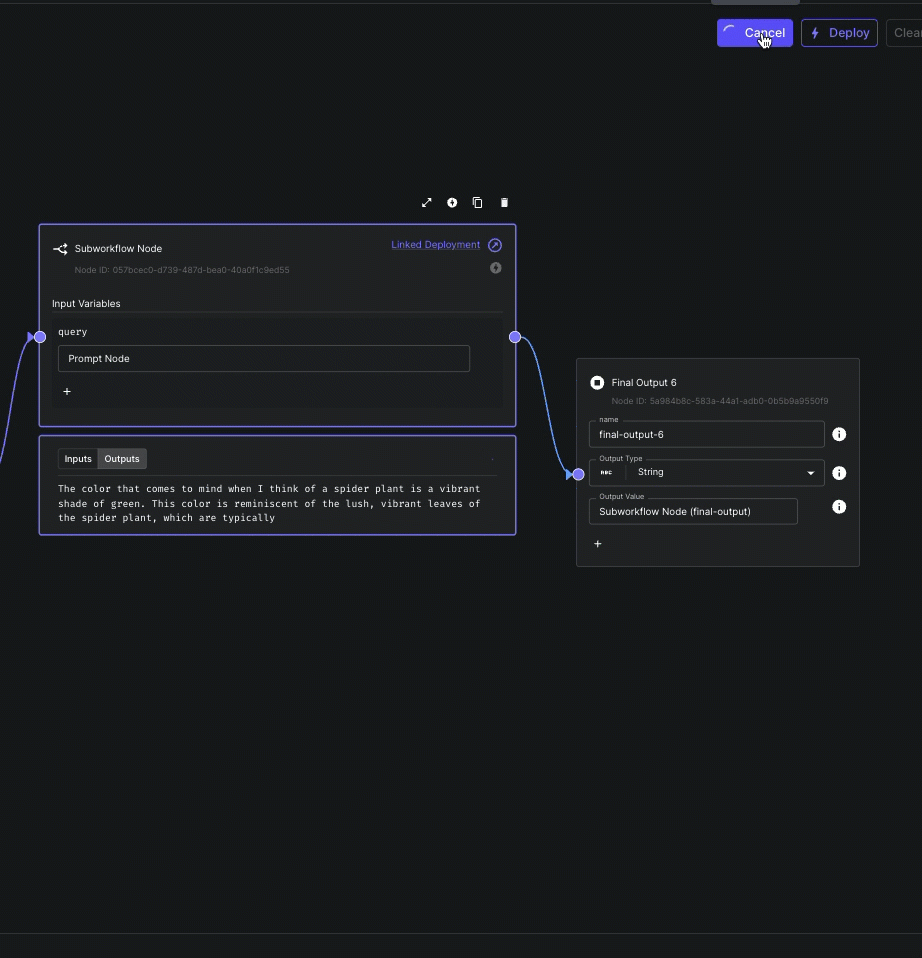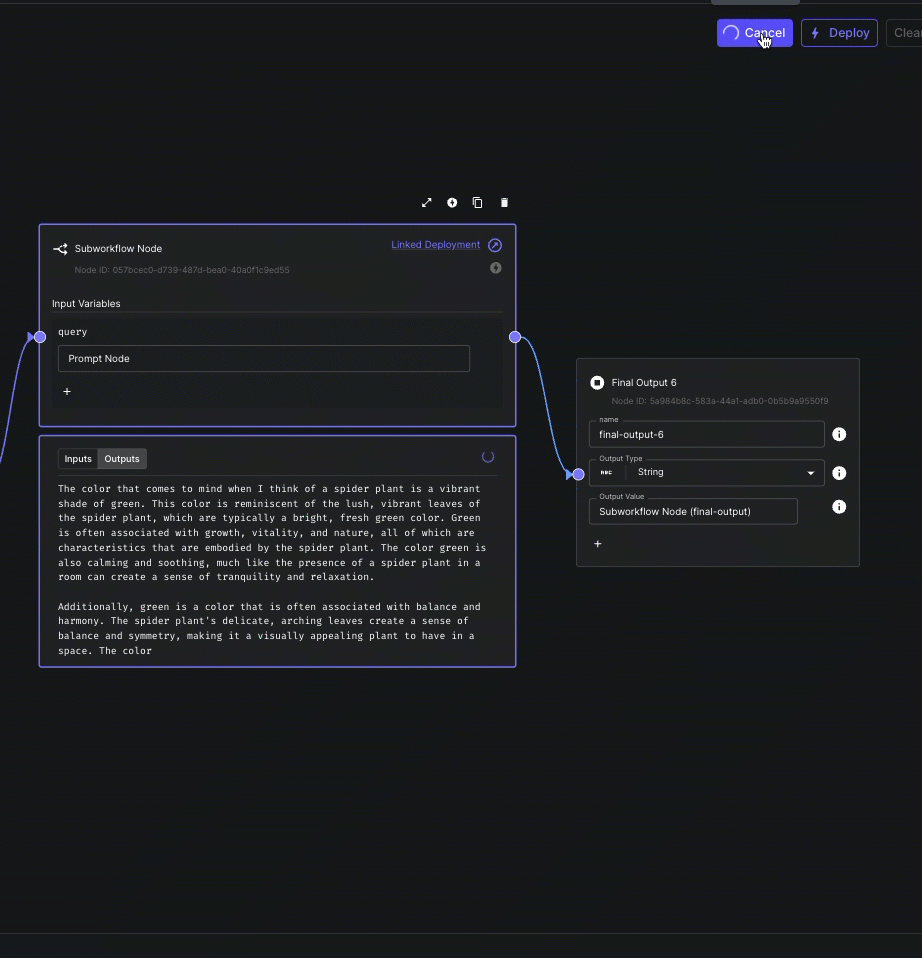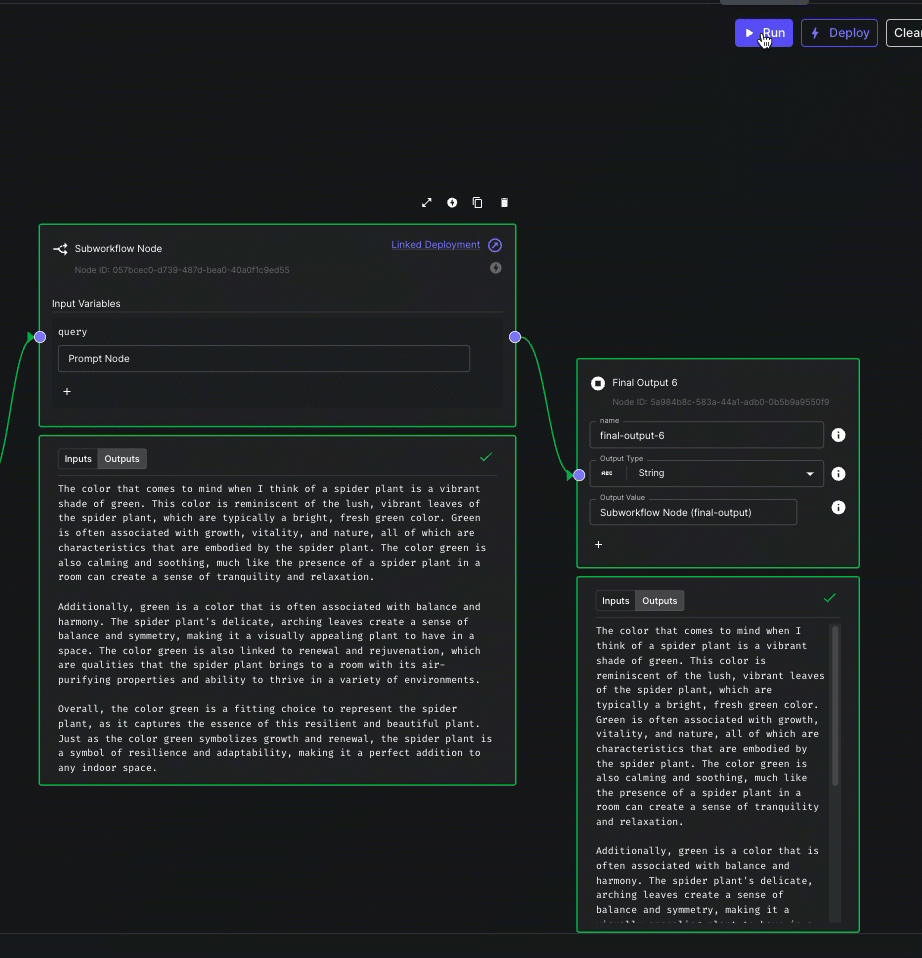
Subworkflow Node Navigation
May 31st, 2024
When viewing the execution details of a Workflow, Subworkflow nodes executed as part of that run will now have a link to its execution page.

Prompt Deployment Actuals Metadata
May 29th, 2024
When submitting execution Actuals for Prompts, you can now optionally include a metadata field. This field can contain arbitrary data, and will be saved and shown in the Executions tab of your Prompt Deployment.

This is particularly helpful if you want to capture feedback/quality across multiple custom dimensions. Learn more in our API docs here.
Replay Workflow from Node
May 29th, 2024
One of the biggest burdens when developing Workflows in Vellum is having to rerun your entire Workflow whenever you want to make a change to just a single node and want to see its downstream effects.
You can now re-run a Workflow from a specific Node! After running a Workflow for the first time, you’ll see this new play icon above each Node.
![]()
Doing so will re-use results from the previous execution for all upstream nodes and only actually execute the target node and all nodes downstream of it.

We hope this helps you decrease iteration cycles and save on LLM costs!
Improvements to Saving Executions as Scenarios & Test Cases
May 29th, 2024
Saving Prompt/Workflow Deployment Executions from production API calls to an Evaluation dataset as Test Cases is a great way to close the feedback loop between monitoring and experimentation. However, this process has historically been time-consuming when you have many Executions to save.
We’ve made a number of improvements to this process:
- You can now multi-select to bulk save Executions as Test Cases
- We now default to the correct Sandbox/Test Suite when saving Executions as Scenarios/Test Cases
- You’ll now see warnings if the Sandbox/Test Suite you’re saving to has required variables that are missing from the Execution
Check out a full demo here:
Prompt Sandbox History Update
May 28th, 2024
Previously, editing past versions of a Prompt Sandbox could be confusing, with unclear indications of which version you were modifying and how it was being saved.
Now, the history view for a Prompt Sandbox is read-only. To edit a previous version, simply click the Restore button, and a new editable version will be created from that specific version.
Workflow Deployment Actuals Metadata
May 28th, 2024
When submitting execution Actuals for Workflows, you can now optionally include a metadata field. This field can contain arbitrary data, and will be saved and shown in the Executions tab of your Workflow Deployment.
This is particularly helpful if you want to capture feedback/quality across multiple custom dimensions.
Guardrail Workflow Nodes
May 23rd, 2024
You can now use Metrics inside of Workflows with the new Guardrail Node! Guardrail Nodes let you run pre-defined evaluation criteria at runtime as part of a Workflow execution so that you can drive downstream behavior based on that Metric’s score.
For example, if building a RAG application, you might determine whether the generated response passes some threshold for Ragas Faithfulness and if not, loop around to try again.

Chat Mode Revamp
May 22th, 2024
Chat Mode in Prompt Sandboxes has received a major facelift! The left side of the new interface will be familiar to anyone using the Prompt Editor, while the rest of the interface retains its functionality with a fresh new look. We’ve also fixed some UX wonk and minor bugs during the restyling process.

Double-Click to Resize Rows & Columns in Prompt Sandboxes
May 22th, 2024
You can now double-click on resizable row and column edges in both Comparison and Chat modes to auto-expand that row/column to its maximum size. If already at maximum size, double-clicking will reset them to their default size. Additionally, in Comparison mode, double-clicking on cell corners will auto-resize both dimensions simultaneously.
Improved Image Support in Chat History Fields
May 22th, 2024
We’ve made several changes to enhance the UX of working with images. Chat History messages now include an explicit content-type selector, making it easier to work with image content using supported models. You can now add publicly-hosted images in multiple ways: by pasting an image URL, pasting a copied image, or dragging and dropping an image from another window.
Additionally, we’ve added limited support for embedded images. You can embed an image directly into the prompt by copy/pasting or dragging/dropping an image file from your computer’s file browser. This method has a 1MB size limit and is an interim solution as we continue to explore image upload and hosting options.



Gemini 1.5 Flash
May 20th, 2024
Google’s Gemini 1.5 Flash model is now available in Vellum. You can add it to your workspace from the models page.
Llama 3 Models on Bedrock
May 14th, 2024
We now support both of the Llama 3 models on AWS Bedrock. You can add them to your workspace from the models page.
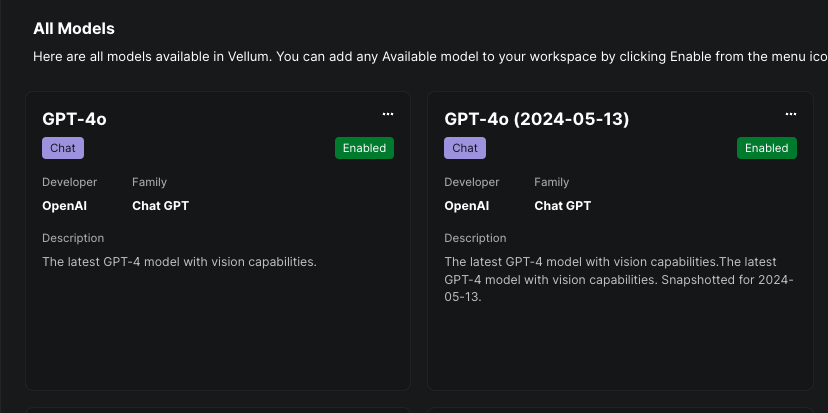
GPT-4o Models
May 13th, 2024
OpenAI’s newest GPT-4o models gpt-4o & gpt-4o-2024-05-13 are now available in Vellum and have been added to all workspaces!
Organization and Workspace Names in Side Nav
May 13th, 2024
You can now view the active Organization’s name and the active Workspace’s name in the left sidebar navigation.
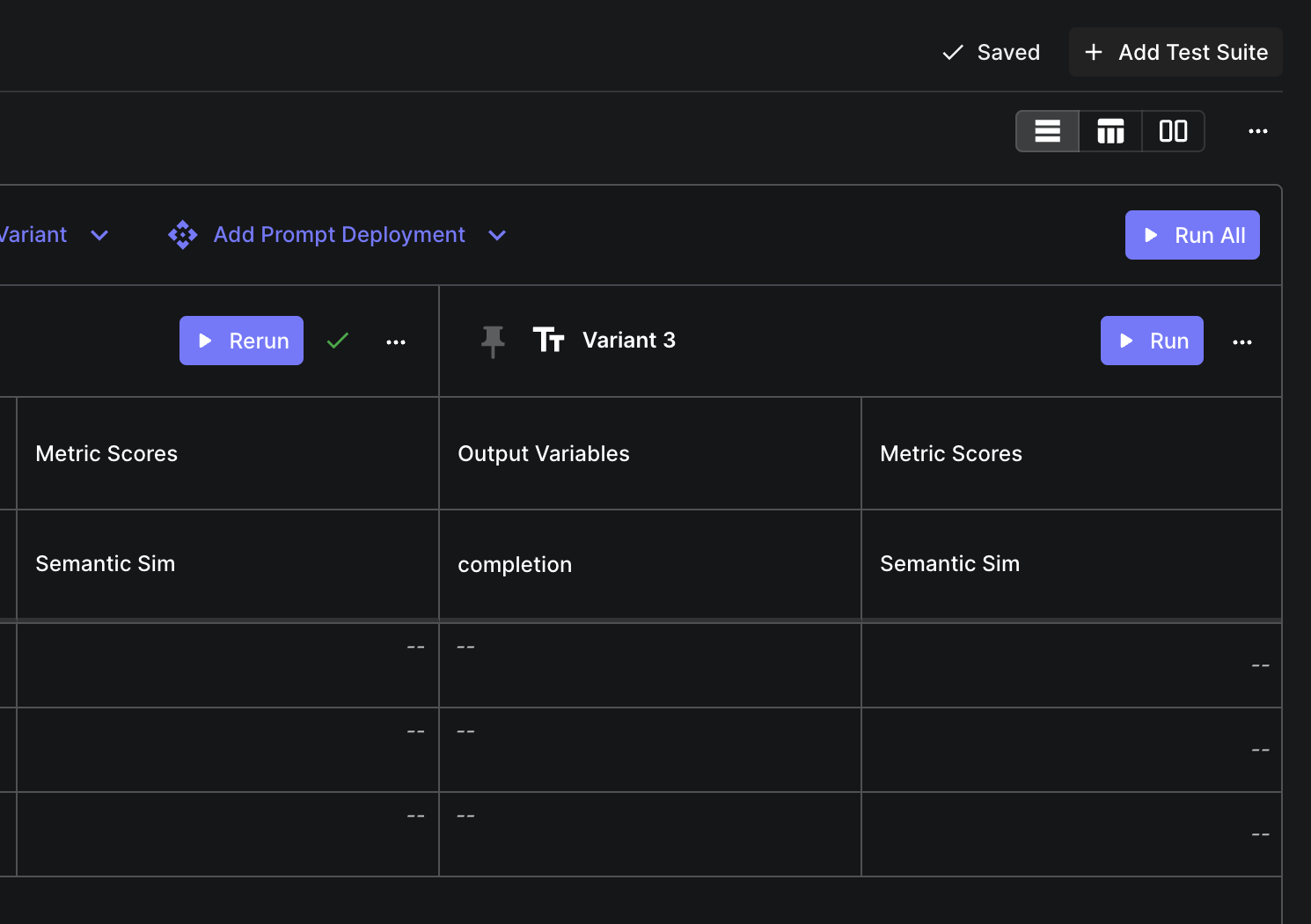
Run All Button on Evaluation Reports
May 10th, 2024
There’s now a “Run All” button on evaluation reports that runs a test suite for all variants. Instead of running each variant individually, you can now run them all with one click.
Prompt Node Monitoring
May 9th, 2024
Vellum is now capturing monitoring data for deployed Prompt Nodes. Whenever a deployed Workflow invokes a Prompt Node, it will now show a link displaying the Prompt Deployment label:
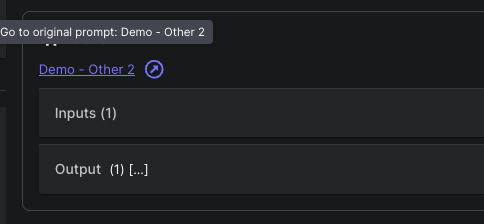
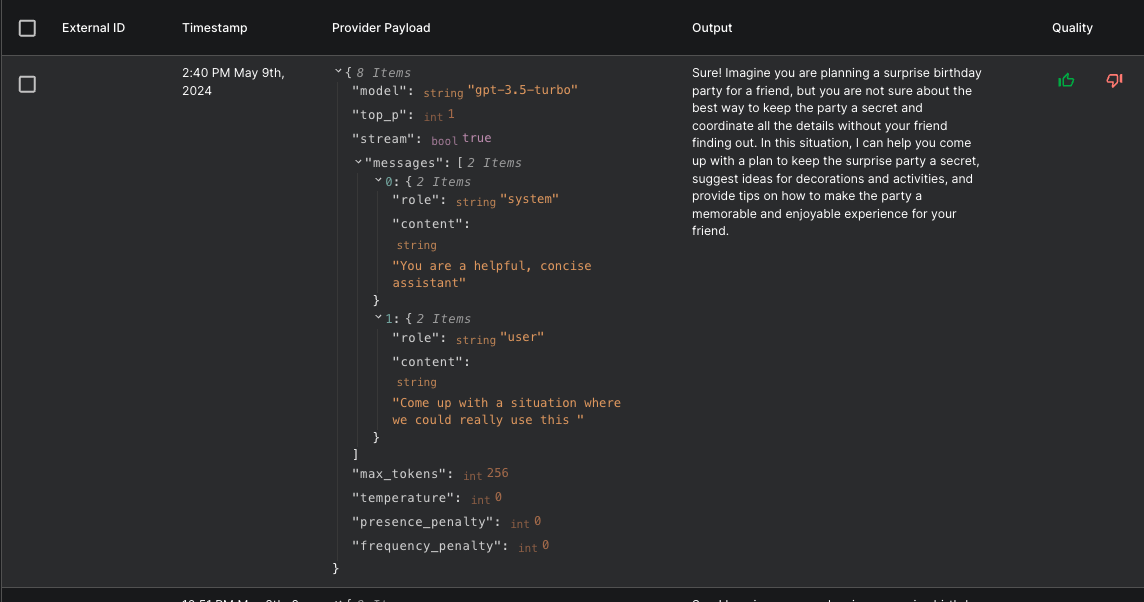
Clicking on the link will take you to the Prompt’s executions page, where you can then see all metadata captured for the execution, including the raw request data sent to the model:
Groq Support
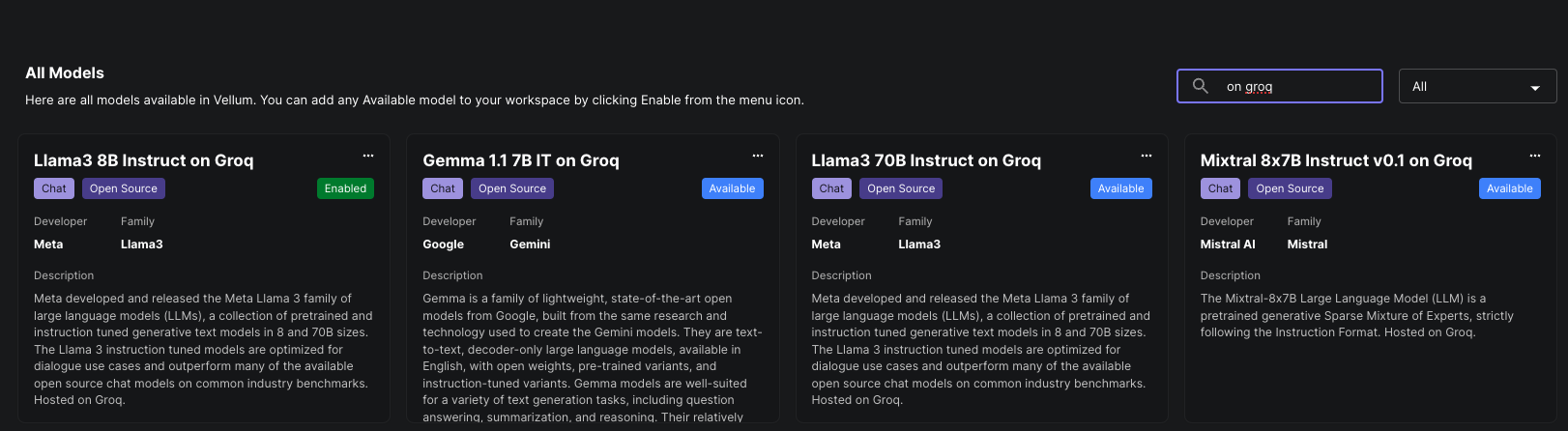
May 9th, 2024
Vellum now has a native integration with the LPU Inference Engine, Groq. All public models on
Groq are now available to add to your workspace. Be sure to add your API key as a Secret named GROQ_API_KEY on the
“Secrets” tab of your Workspace Settings.
Groq is an LLM hosting provider that offers incredible inference speed for open source LLMs, including the recently released (and very hyped!) Llama 3 model.
Function Calling in Prompt Evaluation
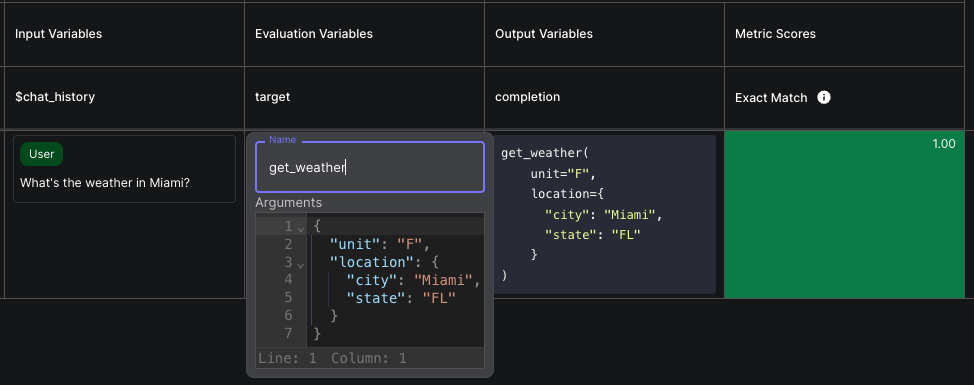
May 8th, 2024
Prompts that output function calls can now be evaluated via Test Suites. This allows you to define Test Cases consisting of the inputs to the prompt, and the expected function call, then assert that there’s a match. For more, check out our docs.
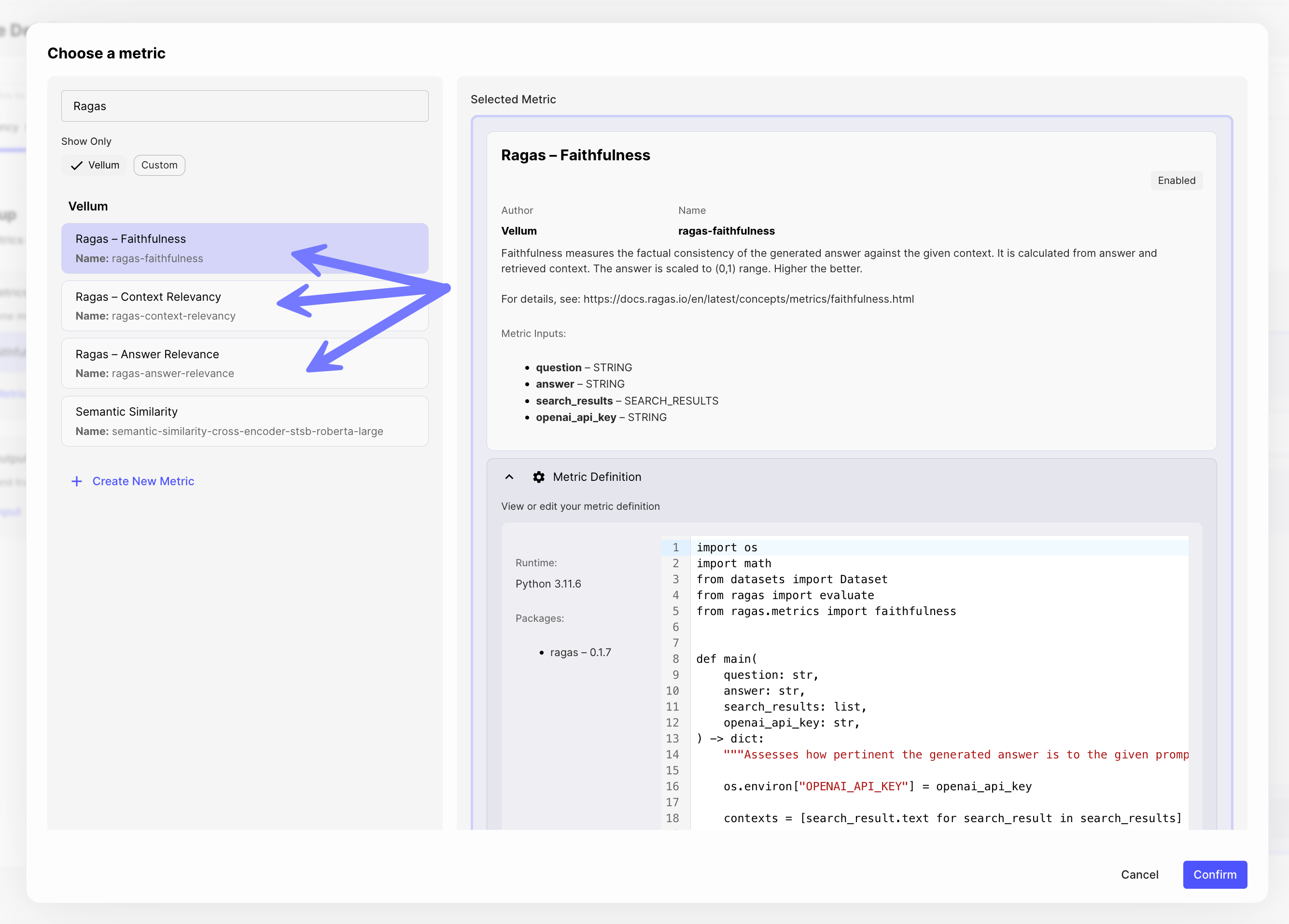
Out-of-Box Ragas Metrics
May 7th, 2024
Test-driven development for your RAG-based LLM pipelines is now easier than ever within Vellum!
Three new Ragas Metrics – Context Revelancy, Answer Relevance and Faithfulness – are now available out-of-box in Vellum. These can be used within Workflow Evaluations to measure the quality of a RAG system.
For more info, check out our new help center article on Evaluating RAG Pipelines.
Subworkflow Node Streaming
May 7th, 2024
Subworkflow Nodes can now stream their output(s) to parent workflows.
This allows you to compose workflows using modular subworkflows without sacrificing the ability to delivery incremental results to your end user.
Note that only nodes immediately prior to Final Output Nodes can have their output(s) streamed.
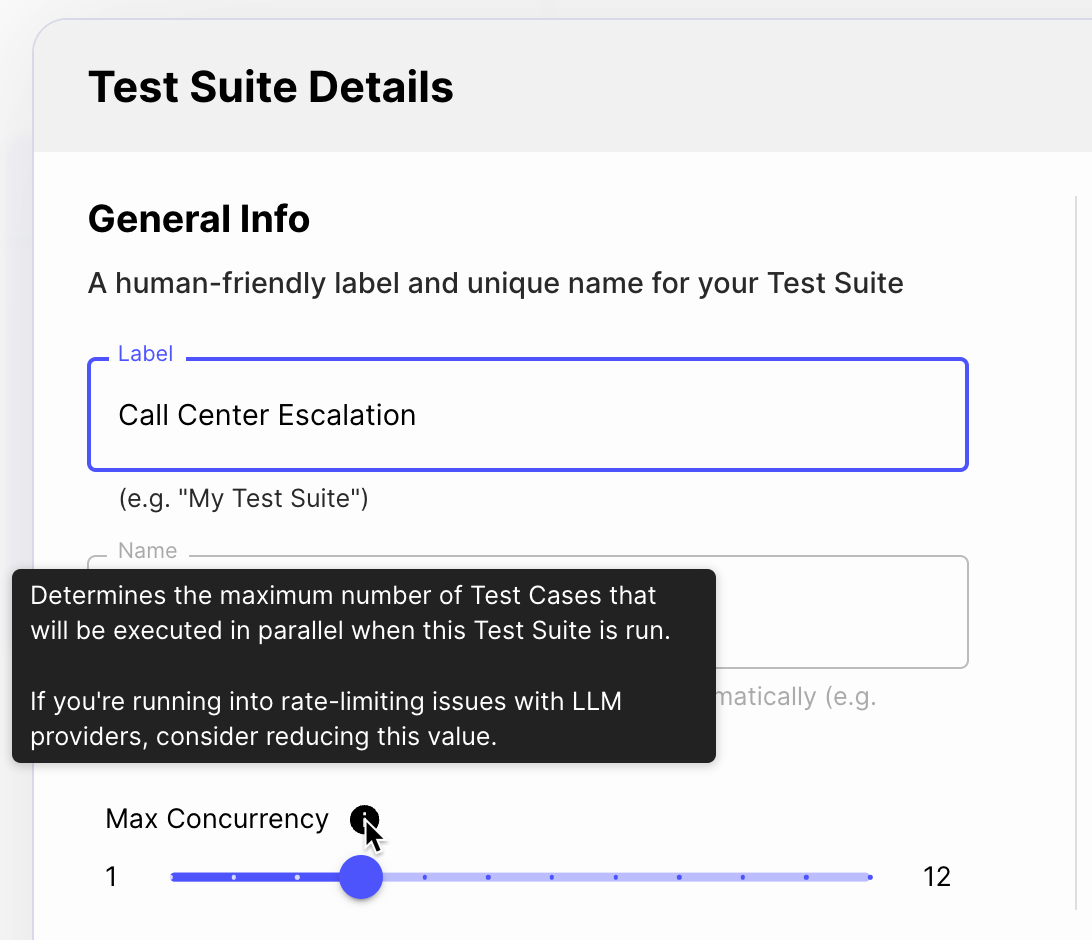
Default Test Case Concurrency in Evaluations
May 4th, 2024
You can now configure how many Test Cases should be run in parallel during an Evaluation. You might lower this value if you’re running into rate limits from the LLM provider, or might increase this value if your rate limits are high.