Changelog | October, 2024
Changelog | October, 2024
AWS Bedrock Support for Anthropic’s Claude 3.5 Sonnet
October 31st, 2024
We’ve added support for Anthropic’s Claude-3-5-sonnet-20241022-v2:0 model on AWS Bedrock.
Google Cloud Vertex AI Support for Anthropic’s Claude 3.5 Sonnet
October 31st, 2024
We’ve added support for Anthropic’s Claude-3-5-sonnet-20241022-v2:0 model on Google Cloud Vertex AI.
Google Cloud Vertex AI Support
Retrieve Workspace Secret or Update Workspace Secret
October 31st, 2024
We’ve added two new API endpoints for retrieving a Workspace Secret and updating a Workspace Secret.
- For retrieving a Workspace Secret, check out our GET API here.
- For updating a Workspace Secret, check out our PATCH API here.
This API is available in our SDKs beginning with version 0.8.30.
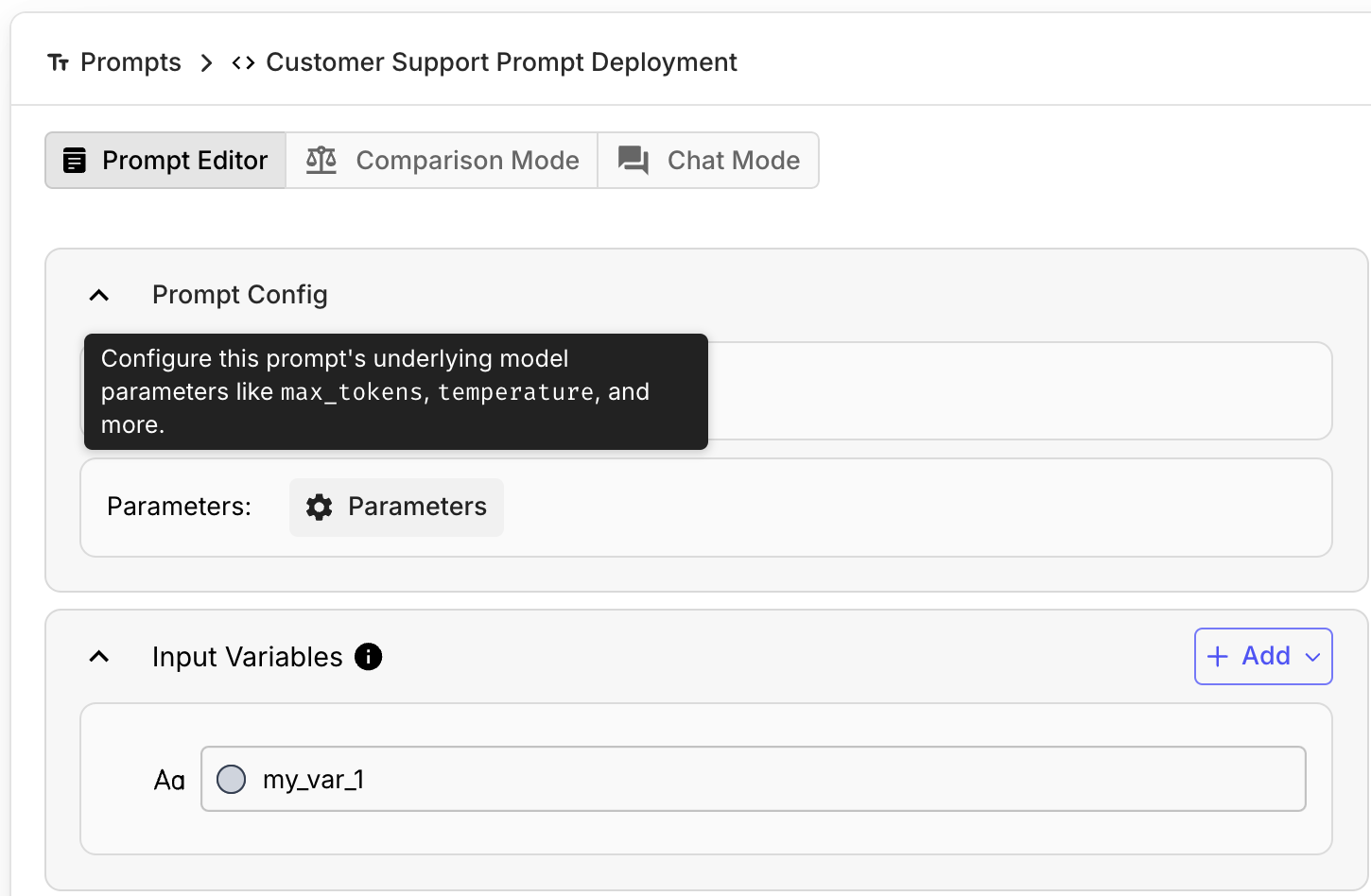
Prompt Timeout Enabled for Prompt Deployments
October 29th, 2024
You can now set timeouts for Prompt Deployments. With this, you can ensure that any Prompt Execution will timeout if it lasts longer than the specified amount of time.
To set a timeout for a Prompt Deployment, navigate to the “Parameters” section within the Prompt Sandbox and scroll down to toggle the “Timeout” setting on. You can then set the timeout duration in seconds. After deploying your Prompt, your Prompt Deployment will respect your configured timeout.
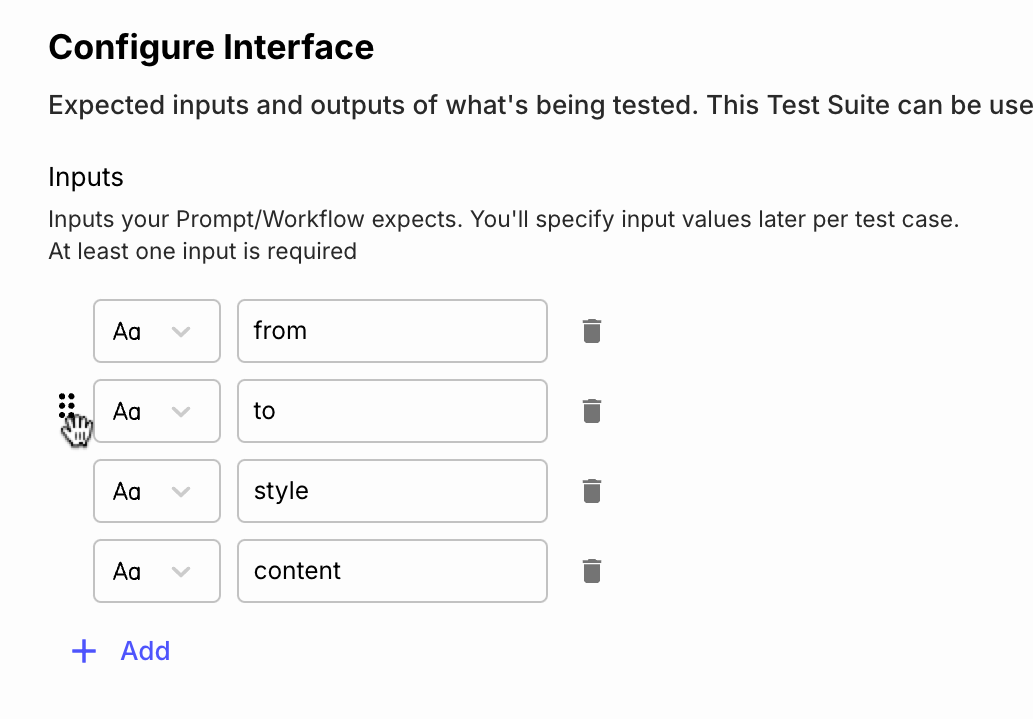
Reorder Test Suite Variables
October 24th, 2024
You can now reorder Input and Evaluation Variables within a Test Suite’s settings page. Drag and drop the variables into the order you prefer. This new order will automatically be reflected in your Evaluation Reports.
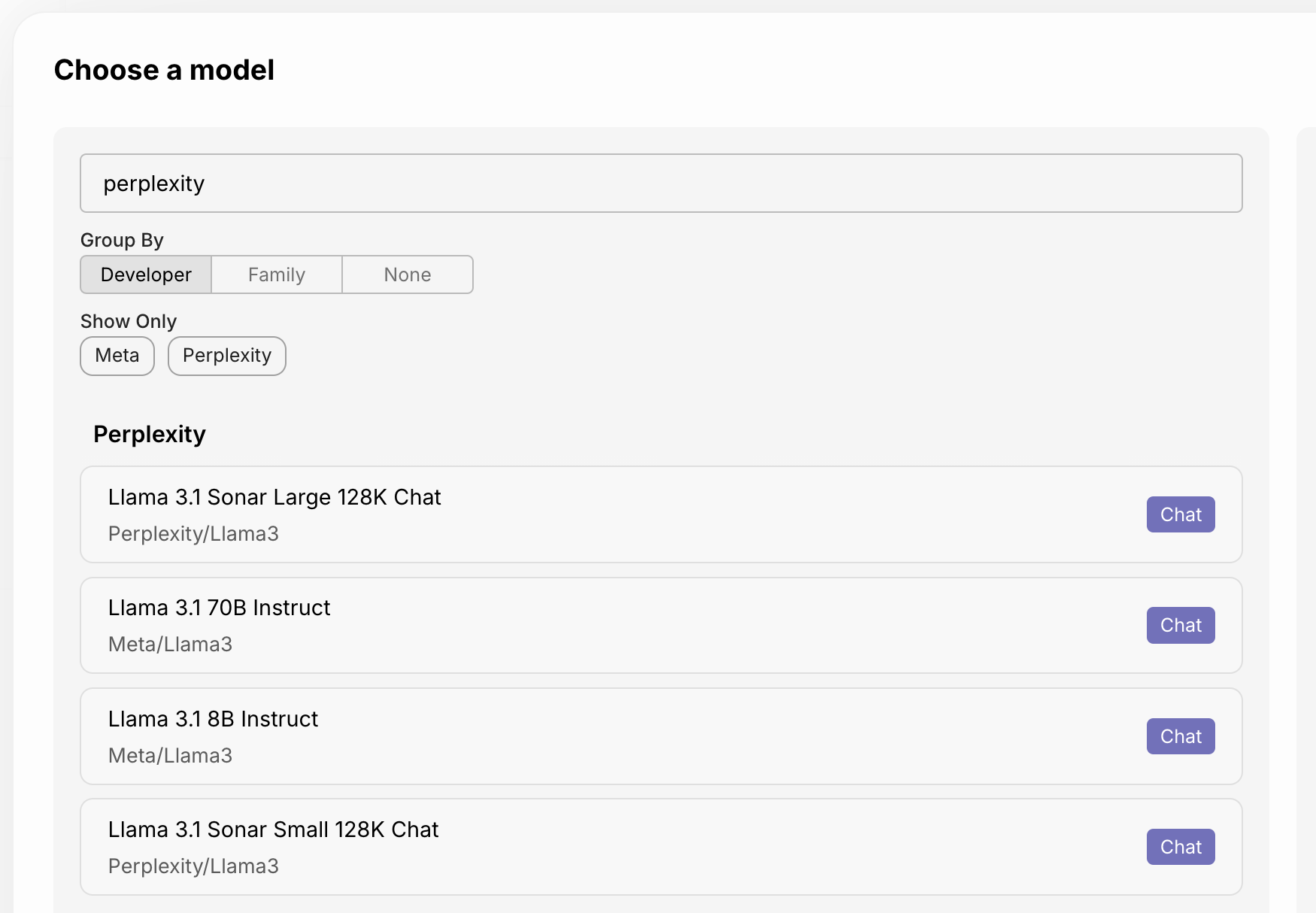
Support for Perplexity AI’s Online Models
October 24th, 2024
We’ve added support for Perplexity AI’s newest Sonar Online models, which provide real-time web search capabilities integrated directly into the language model.
Check out Perplexity AI’s online models here:
The supported models are:
- LLama 3.1 Sonar Small 128k Online
- LLama 3.1 Sonar Large 128k Online
- LLama 3.1 Sonar Huge 128k Online
These models offer several key features:
- Real-time web search: The models can perform live internet searches to retrieve up-to-date information.
- Contextual understanding: They can interpret search results in the context of the user’s query.
- Source citation: The models provide citations for information sourced from the web.
- Multilingual support: They can understand and generate content in multiple languages.
- Long-context understanding: The models can handle extended conversations and complex queries.
To use these models in Vellum, simply select the appropriate Sonar Online model when configuring your Prompt or Workflow. The model will automatically perform web searches when needed to supplement its knowledge and provide the most current and relevant information.
Note: Using these models may result in slightly longer processing times due to the real-time web search functionality, but they offer significantly enhanced capabilities for tasks requiring up-to-date information.
Support for Perplexity AI Models
October 24th, 2024
We’ve added support for Perplexity AI as one of our newest model hosts!
Along with the launch of the Perplexity AI integration, we’ve added the following models:
- Perplexity AI: LLama 3.1 Sonar Small 128k Chat
- Perplexity AI: LLama 3.1 Sonar Large 128k Chat
- Perplexity AI: LLama 3.1 8B Instruct
- Perplexity AI: LLama 3.1 70B Instruct
Support for LLama 3.1 Lumimaid 70B and Magnum v4 72B models on OpenRouter
October 24th, 2024
We’ve added support for the LLama 3.1 Lumimaid 70B and Magnum v4 72B models on OpenRouter!
Support for Gemini 1.5 Flash 8B Model
October 23nd, 2024
In addition to the existing support for the Gemini 1.5 models, we’ve added support for the Gemini 1.5 Flash 8B model to Vellum!
Claude 3.5 Sonnet 2024-10-22 Live!
October 22nd, 2024
We’ve added support for Anthropic’s latest 10/22/2024 snapshot of Claude 3.5 Sonnet to Vellum!
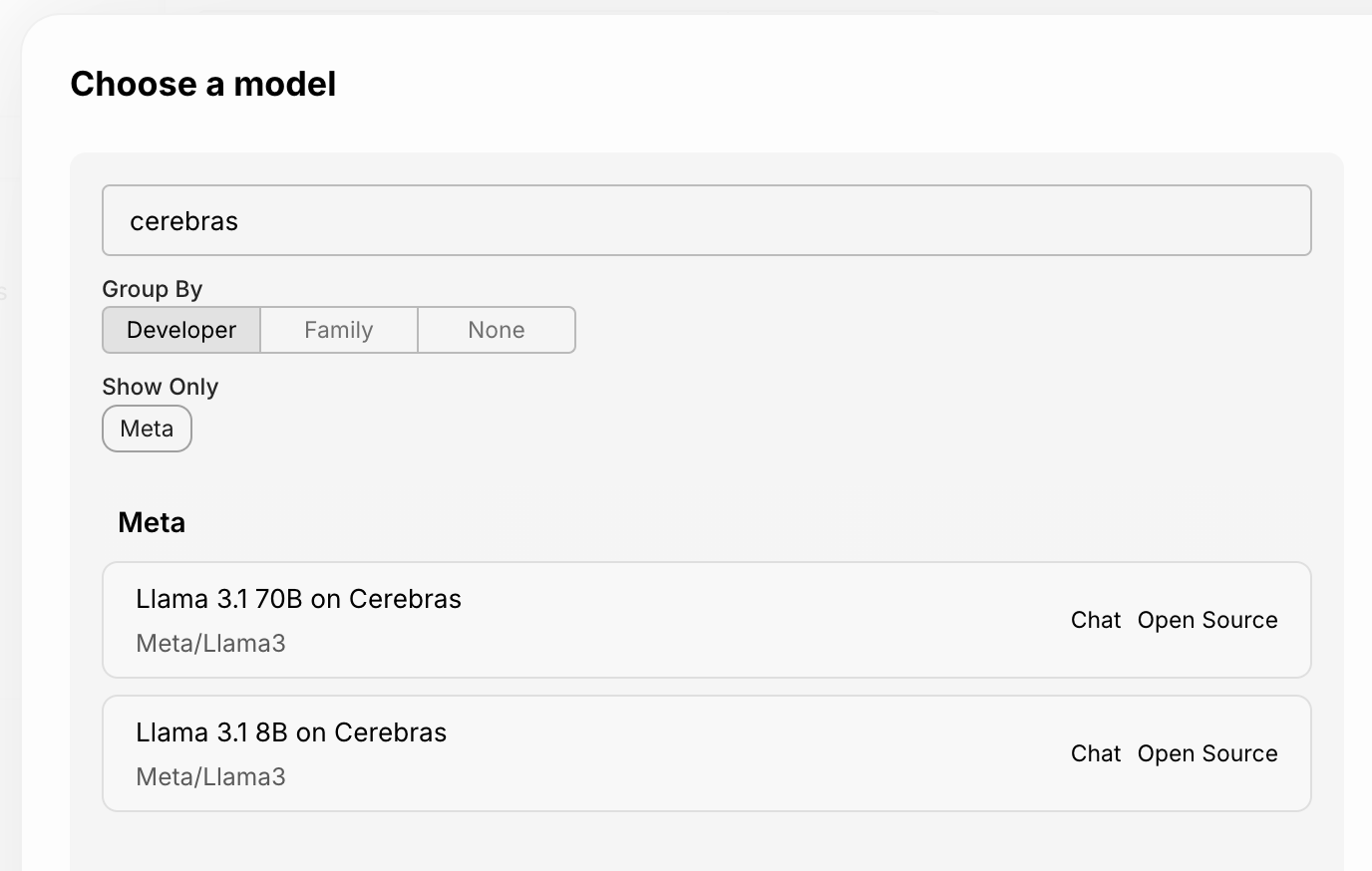
Support for Cerebras-AI Models
October 22nd, 2024
We’ve added support for Cerebras-AI to Vellum!
Along with the launch of the Cerebras-AI API, we’ve added the following models:
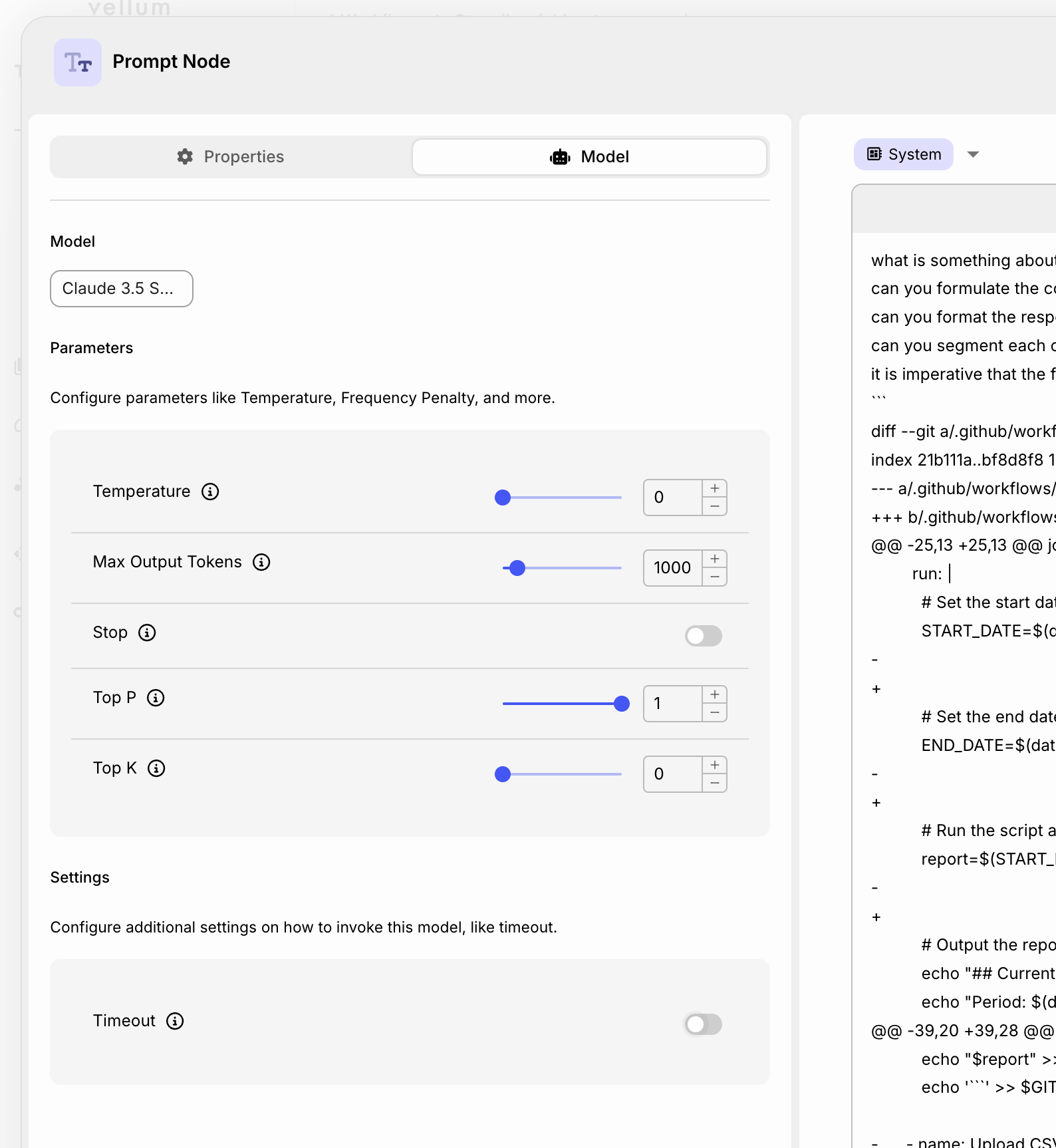
Configurable Prompt Node Timeouts
October 22nd, 2024
You can now set a max timeout for Prompt Nodes within Workflows. With this, you can ensure that no one LLM invocation will run for too long and slow down the Workflow overall and instead, fail early if it does.
To set a timeout for a Prompt Node, simply navigate to the new “Settings” section and toggle the “Timeout” setting on. You can then set the timeout duration in seconds.
New API for Listing Entities in a Folder
October 20th, 2024
We now have a new API endpoint for listing all entities in a folder. This endpoint allows you to retrieve all entities in a folder, including subfolders, with a single API call. You can use this endpoint to quickly get a list of all entities in a folder with high-level metadata about them.
For details, check out our API Reference here.
This API is available in our SDKs beginning version 0.8.25.
Datadog and Webhook Logging Beta Integrations
October 15th, 2024
Logs for your Prompts, Workflows and Documents can now be streamed to Datadog and external Webhooks. This is useful if you want deeper insight into key events that happen in Vellum in your external systems. For example, you might set up a Datadog alert that fires when there are multiple subsequent failures when executing a Workflow Deployment.
These integrations are currently in beta. If you’d like to participate in the beta period and want help setting up the integration, please contact Vellum Support.
Eva Qwen and Rocinante Added to OpenRouter Integration
October 13th, 2024
We’ve added 2 additional new models to Vellum via our OpenRouter integration!
- Eva Qwen 2.5 14B - A powerful model based on the Qwen architecture.
- Rocinante 12B - A versatile 12 billion parameter model.
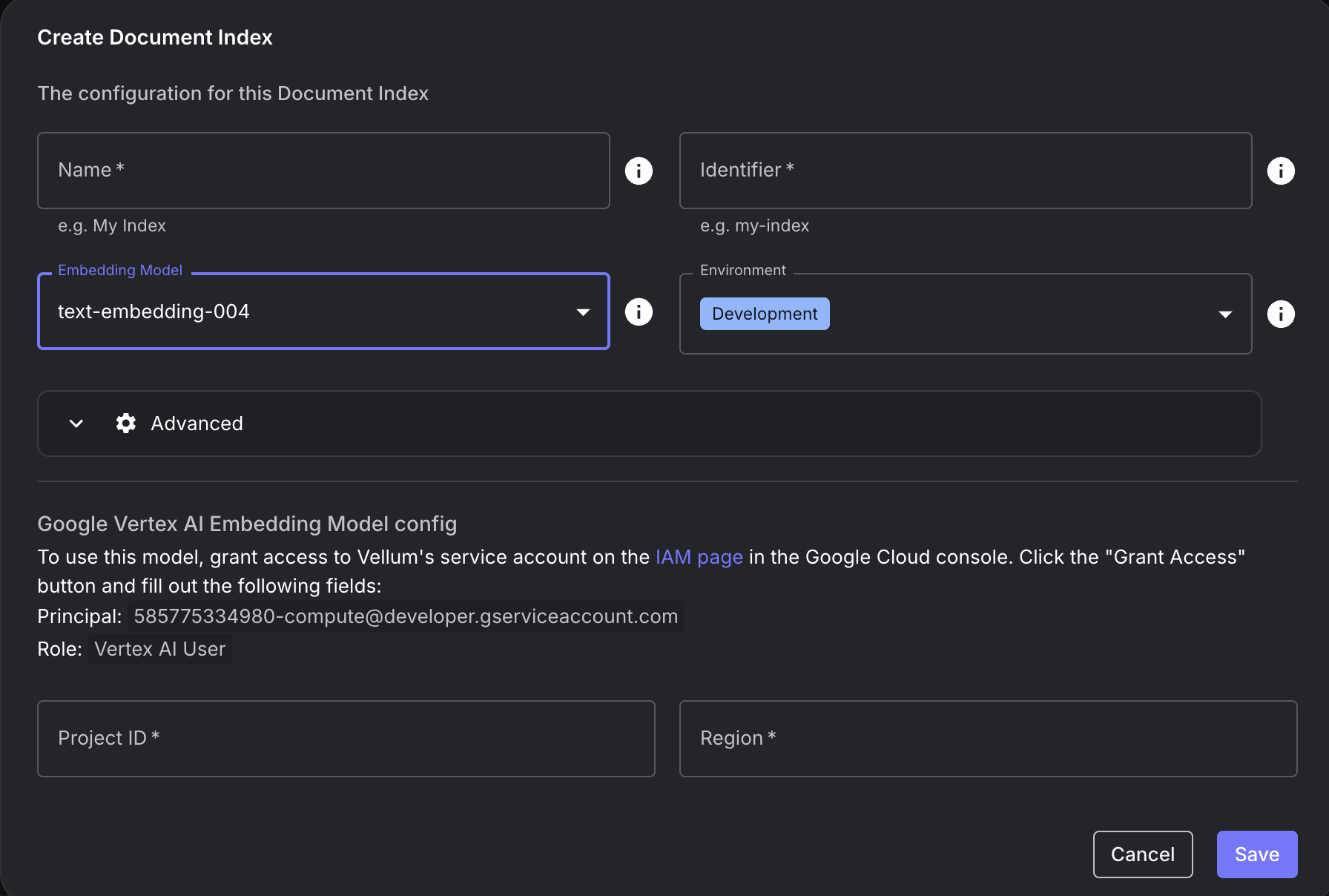
Vertex AI Embedding Model Support
October 15th, 2024
We’re excited to announce the addition of the Vertex AI embedding models text-embedding-004 and text-multilingual-embedding-002 to Vellum!
These models can be selected when creating a Document Index.
New Models Added to OpenRouter Integration
October 11th, 2024
We now have the addition of 8 new models integrated into Vellum via our OpenRouter integration:
- Magnum v2 72B - A powerful model designed to achieve prose quality similar to Claude 3 models.
- Nous: Hermes 3 405B Instruct - A frontier-level, full-parameter finetune of the Llama-3.1 405B foundation model.
- NousResearch: Hermes 2 Pro - Llama-3 8B - An upgraded version of Nous Hermes 2 with improved capabilities.
- Nous: Hermes 3 405B Instruct (extended) - An extended context version of Hermes 3 405B Instruct.
- Goliath 120B - A large LLM created by combining two fine-tuned Llama 70B models.
- Dolphin 2.9.2 Mixtral 8x22B - An uncensored model designed for instruction following, conversation, and coding.
- Anthropic: Claude 3.5 Sonnet (self-moderated) - A faster, self-moderated endpoint of Claude 3.5 Sonnet.
- Liquid: LFM 40B MoE - A 40.3B Mixture of Experts (MoE) model for general-purpose AI tasks.
These new models offer a wide range of capabilities, from improved prose quality and instruction following to extended context lengths and specialized tasks like coding. Users can now leverage these models in their Vellum projects, expanding the possibilities for AI-powered applications.
Workflow Edge Type Improvements
October 10th, 2024
In the past, it could be quite difficult to achieve a perfectly straight line between two Nodes in a Workflow with the “smooth-step” edge type, but those days are behind us, friends.
You’ll now see that your edges will automagically snap into straight-line connectors whenever they’re close-to-horizontal.
AutoLayout and AutoConnect for Workflows
October 10th, 2024
Two exciting new features have been added to Workflows — AutoLayout and AutoConnect.
AutoLayout allows you to instantly organize your workflow via algorithm, making it easier than ever to tame even the most-unruly of Workflows.
AutoConnect will automatically connect any unconnected Nodes in your Workflow by creating edges from left to right (more-or-less).
Both of these features are accessible via new buttons in the bottom left toolbar in your Workflow Sandboxes.
In the event that you only want to use AutoConnect or AutoLayout on a specific subset of Nodes, simply drag to select and you’ll see a new temporary toolbar that allows you to do just that.
Reorder Entities in Evaluation Reports
October 9th, 2024
You can now reorder entities in the Evaluation Report table. Simply select the “Reorder” option in the entity column’s menu to adjust the order to your preference.
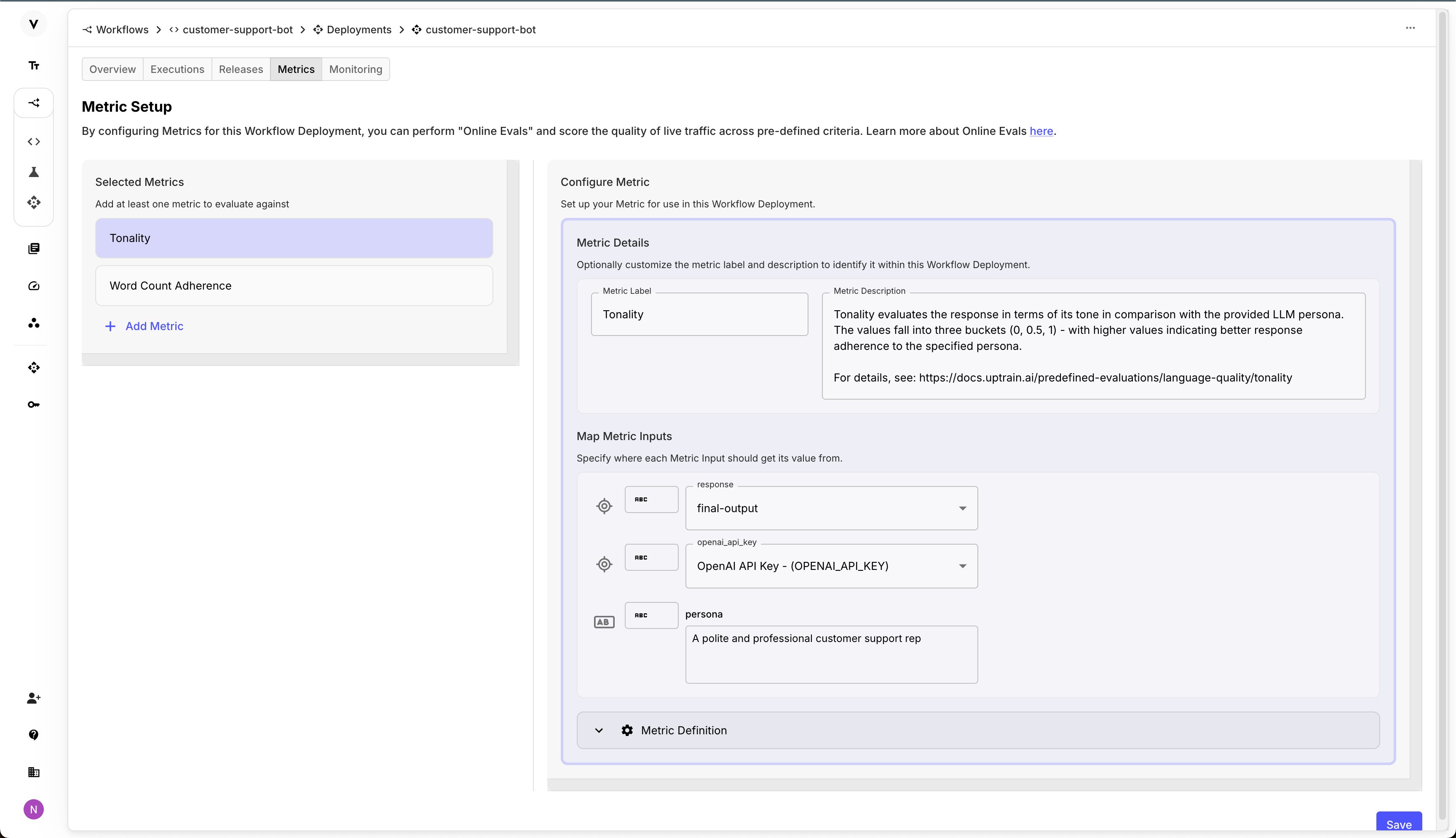
Online Evaluations for Workflow and Prompt Deployments
October 3rd, 2024
We’re excited to announce the launch of Online Evaluations for Workflow and Prompt Deployments! This new feature allows you to configure Metrics for your Deployments to be evaluated in real-time as they’re executed. Key highlights include:
- Continuous Assessment: Automatically evaluate the quality of your deployed LLM applications as they handle live requests.
- Flexible Configuration: Set up multiple Metrics to assess different aspects of your Deployment’s performance.
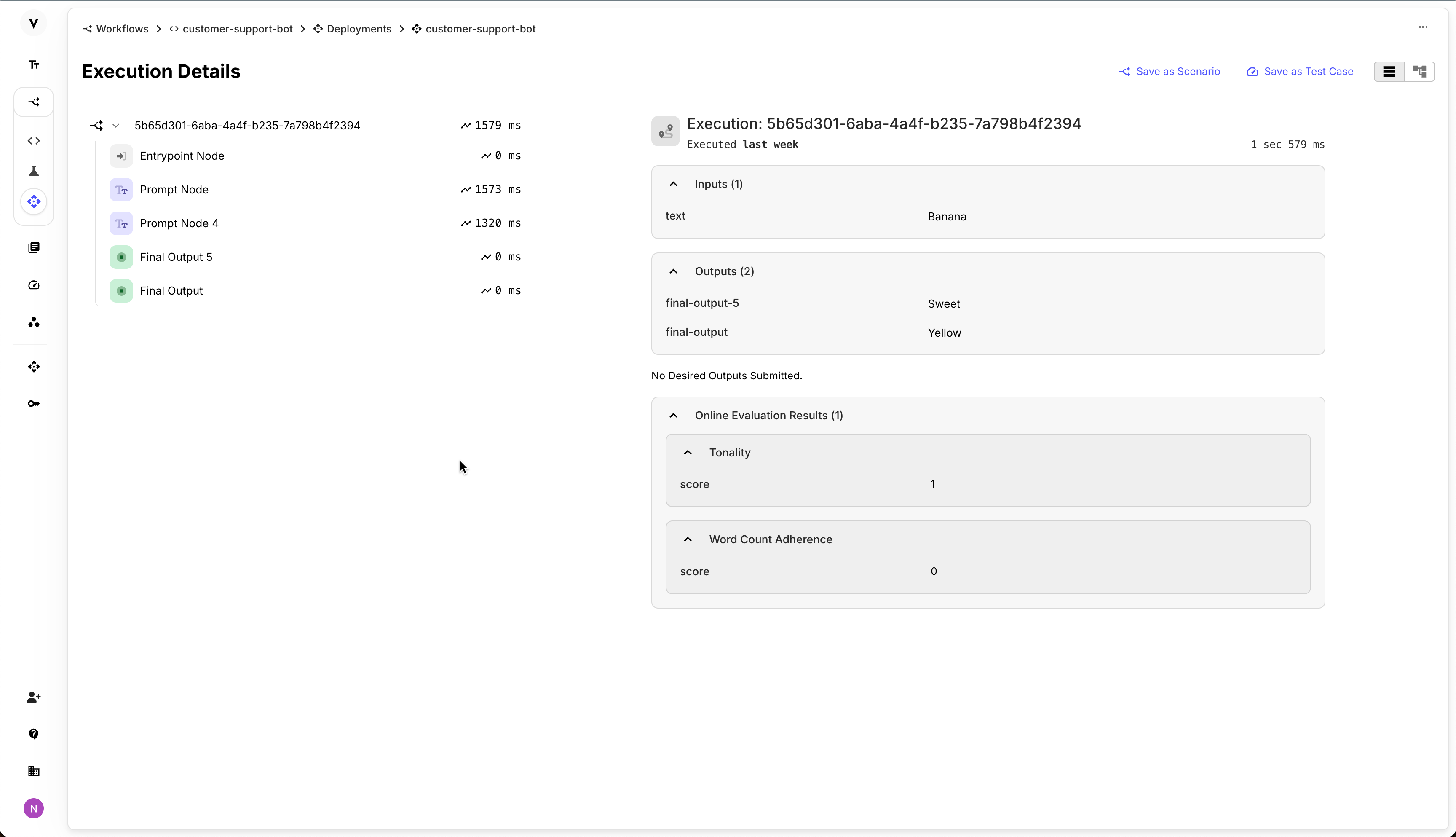
- Easy Access to Results: View evaluation results directly in the execution details of your Deployments.
It works by configuring Metrics for your Workflow or Prompt Deployment in the new “Metrics” tab.
Once configured, every execution of your Deployment will be evaluated against these Metrics. You can then view the results alongside the execution details.
For more details on how to get started with Online Evaluations, check out our help documentation.
OpenRouter Model Hosting + WizardLM-2 8x22B
October 2nd, 2024
We’ve added OpenRouter as a new model host in Vellum! OpenRouter provides access to a wide range of AI models through a single API, expanding the options of models available to our users.
As part of our new OpenRouter integration, we’re pleased to introduce the WizardLM-2 8x22B model to our platform. WizardLM-2 8x22B is known for its strong performance across various natural language processing tasks and is now available for use in your Vellum projects.
Prompt Caching Support for OpenAI
October 2nd, 2024
Today OpenAI introduced Prompt Caching for GPT-4o and o1 models. Subsequent invocations of the same prompt will produce outputs with lower latency and up to 50% reduced costs.
To follow this, we’ve begun capturing cache tokens in Vellum’s monitoring layer. With this update, you’ll now see the number of Prompt Cache Tokens used by a Prompt Deployment’s executions if it’s backed by an OpenAI model. This new monitoring data can be used to help analyze your cache hit rate with OpenAI and optimize your LLM spend.
Filter and Sort on Metric Scores
October 1st, 2024
You can now filter and sort on a Metric’s score within Evaluation Reports. This makes it easy to find all Test Cases that failed below a given threshold for a given Metric.
