Maximize LLM Development Quality with Vellum's Evaluations
Ensuring model quality is challenging, because prompts need to work effectively and consistently over a wide range of potential inputs. When modifying a Prompt, adjusting parameters, or switching models, the likelihood of regression is high. This is where quantitative evaluation comes in.
Vellum’s answer to quantitative evaluation are Test Suites and Metrics. Unlike Comparison Mode and Chat Mode, where the output of each Scenario is qualitatively evaluated by visual inspection, Test Suites use Metrics that return scores between 0 and 1 to provide a more objective measure of quality over a wider range of scenarios. This is especially important when your prompt’s coverage needs scale and visual inspection is no longer feasible, which typically happens when you have 10+ scenarios.
Test Suites cover common use cases in LLM development:
- Test Driven Development of Prompts/Workflows in a Sandbox
- Performance testing on large numbers of Scenarios
- Regression testing before deploying a change to a Prompt or Workflow
- Evaluating external entities
If you’re looking to improve the velocity or quality of your LLM development, Test Suites could be your answer.
Getting Started
Create a Test Suite
You can create standalone Test Suites through the Test Suites page in the Evaluations tab. You can also create Test Suites starting from a Prompt or Workflow Sandbox. Here, we’ll begin by creating a Test Suite from a Prompt Sandbox.
- From your Prompt Sandbox, click on Evaluations sub-tab
- Click “Create New Test Suite” if you haven’t set up a Test Suite for this Prompt Sandbox yet or click the gray “Add Test Suite” button on the right of the page
- The “label” and “name” fields are autopopulated with the name of your Sandbox
- Open the “Interface Configuration” to see the expected inputs/outputs for this Test Suite. This is also autopopulated from your Sandbox.
- If you are creating a Test Suite from scratch, you can customize the inputs/outputs to meet your needs. For now, leave this as it is and click next to start setting up your Metrics.
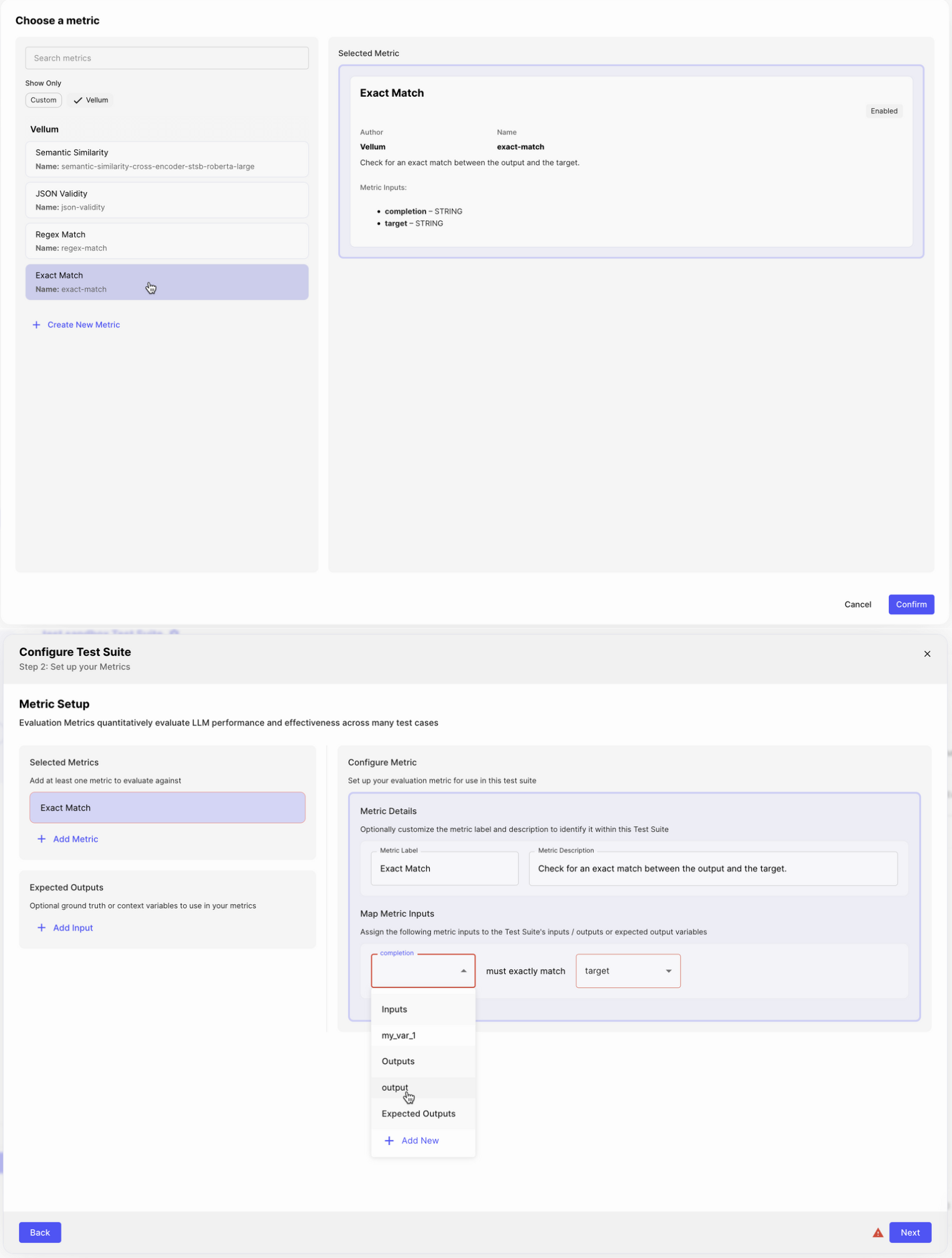
- Click the “Add Metric” button to select one or more Metrics to evaluate your output against
- Select “Exact Match” from the list of available Metrics. To learn how to create Custom Metrics that appear in this list, see Vellum’s Metrics
- Press “Confirm” to start mapping the Metric to this Test Suite
- First, select “Completion” to map the input to the output of your Prompt
- Next, select “Target” and then “Add New” in the dropdown to create a new expected output variable that’s mapped to this input
- Press “Next” in the bottom right
Well done! You’ve now created a Test Suite with the Exact Match Metric to check for whether the output is desirable.
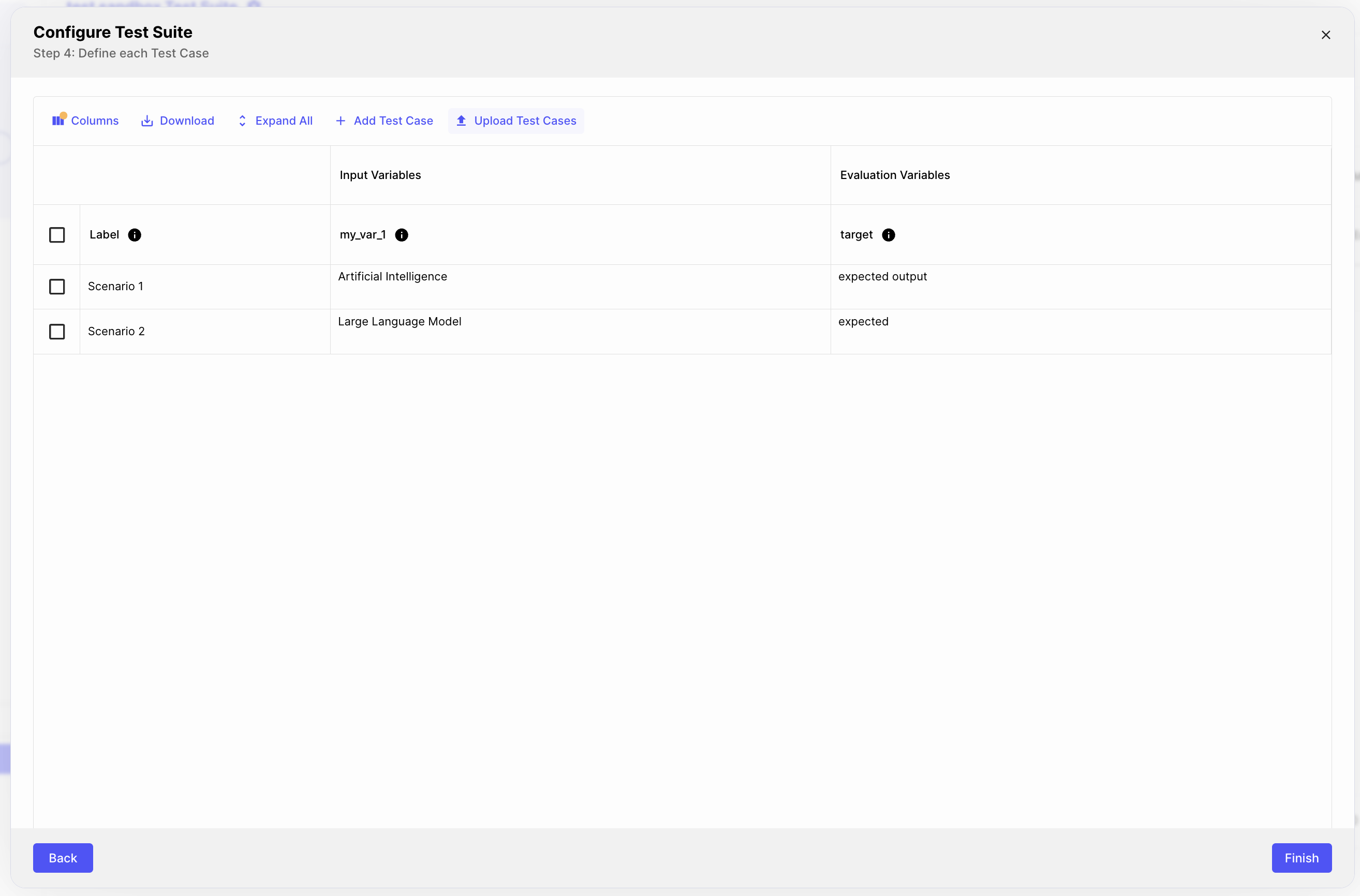
Create a Test Case
Test Cases are analogous to Scenarios. A Test Case by default will have a column for each input and output variable expected by your Test Suite, as well as columns for any expected output variables required by your selected Metric. When a Test Suite is run, Vellum will iterate over every Test Case it contains. For each Test Case, it will feed the provided inputs into the Prompt, Workflow, or entity being tested. The output will be passed to the Metric based on your mapping in the previous step, and a score will be provided based on the Metric being used.
With this Test Suite created, you should be on a step that asks you how you want to initialize your Test Cases.
Select “Start from Scenarios” which will autopopulate test cases for you from Scenarios in your Sandbox.
To create additional Test Cases, follow these steps:
- Click the blue ”+ Add Test Case” button just below the tab to add a new Test Case row
- You can leave the “Label” field alone for now - it’s used to help you visually identify your Test Cases
- Enter a value for each of your input variables. For example, if you have an input variable
user_age, you may enter “28”. - Enter a value for each of your expected output variables
- Click outside of your Test Case row to save. You should get a notification that it was successful.
- Click “Finish” to exit the Test Suite creation wizard
Almost there! Now that you have your Test Cases added, you’re ready to run it against your Prompt.
Run a Test Suite
This Test Suite is automatically added to the current Prompt Sandbox you are in. To evaluate your Prompt, simply click the blue Run button.
The Test Suite can also be run by any Prompt or Workflow that uses the same input variables you configured earlier. Let’s try it.
- Navigate to any Prompt Sandbox in the “Prompts” tab
- Click the gray “Add Test Suite” at the top right of the page
- Attach a Test Suite by clicking on “Use Existing Test Suite” and selecting your Test Suite from the dropdown
- Press the blue “Run” to execute the Test Suite
Download via API
We also support viewing your Test Suite Run results via the API. Check out our docs on Test Suite Runs to learn how to view existing runs. We also embed ready-to-use code snippets within the app itself for each executable column on the evaluations table.
Advanced Usage
Multiple Metrics
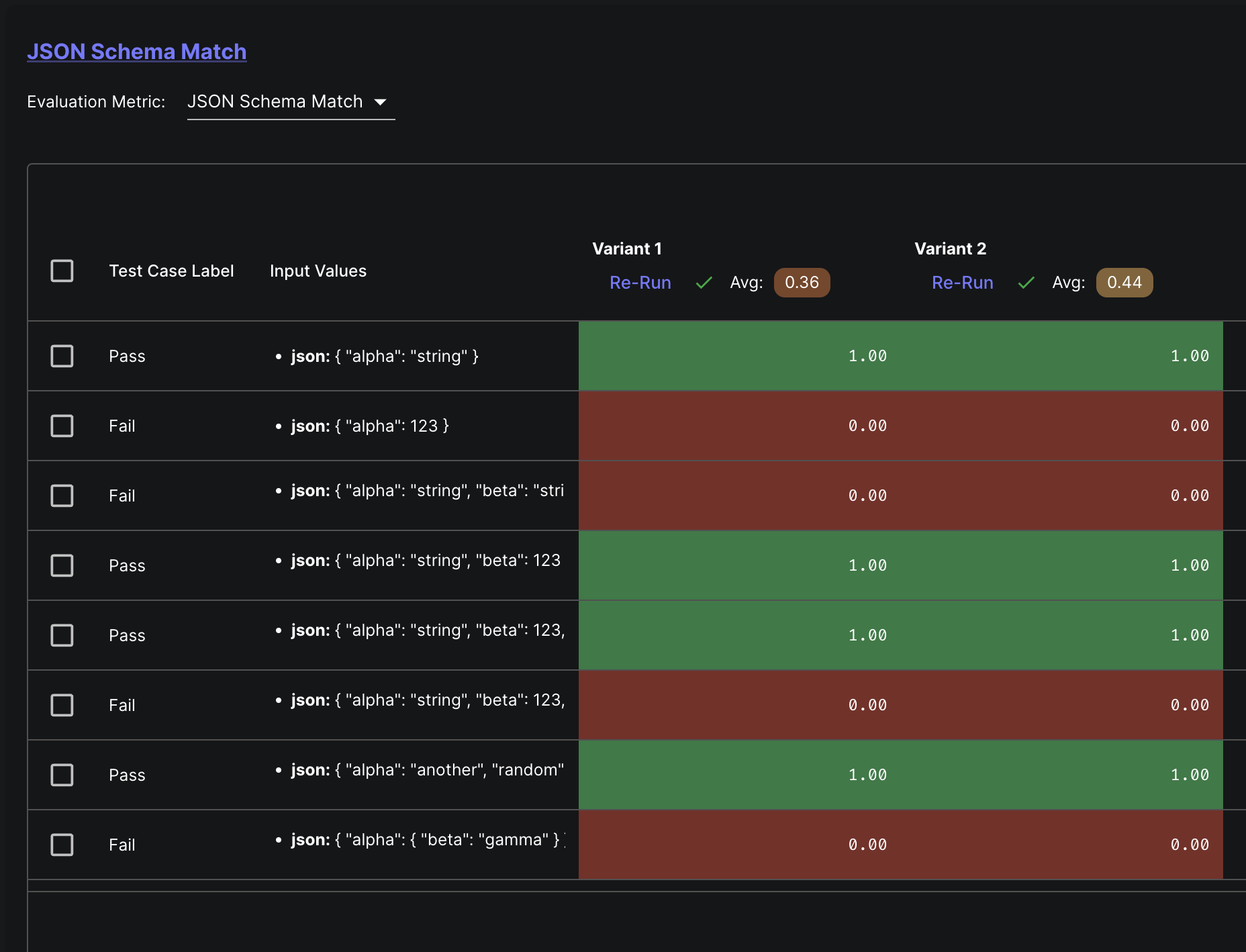
It’s possible for a Test Suite to have multiple Metrics run simultaneously. This is often desirable when the output is complex and must meet multiple criterion. For example, you may want to validate that an output semantically means “I’m very happy”, but must contain the word “ecstatic”.
Additional Metrics can be configured on an existing Test Suite under the “Metric Setup” section of the “Test Suite Details” page. Any additional columns needed by that Metric will be editable under the “Test Cases” tab.
When running the Test Suite, you’ll see columns displaying the results for each Metric that’s been added to the Test Suite.
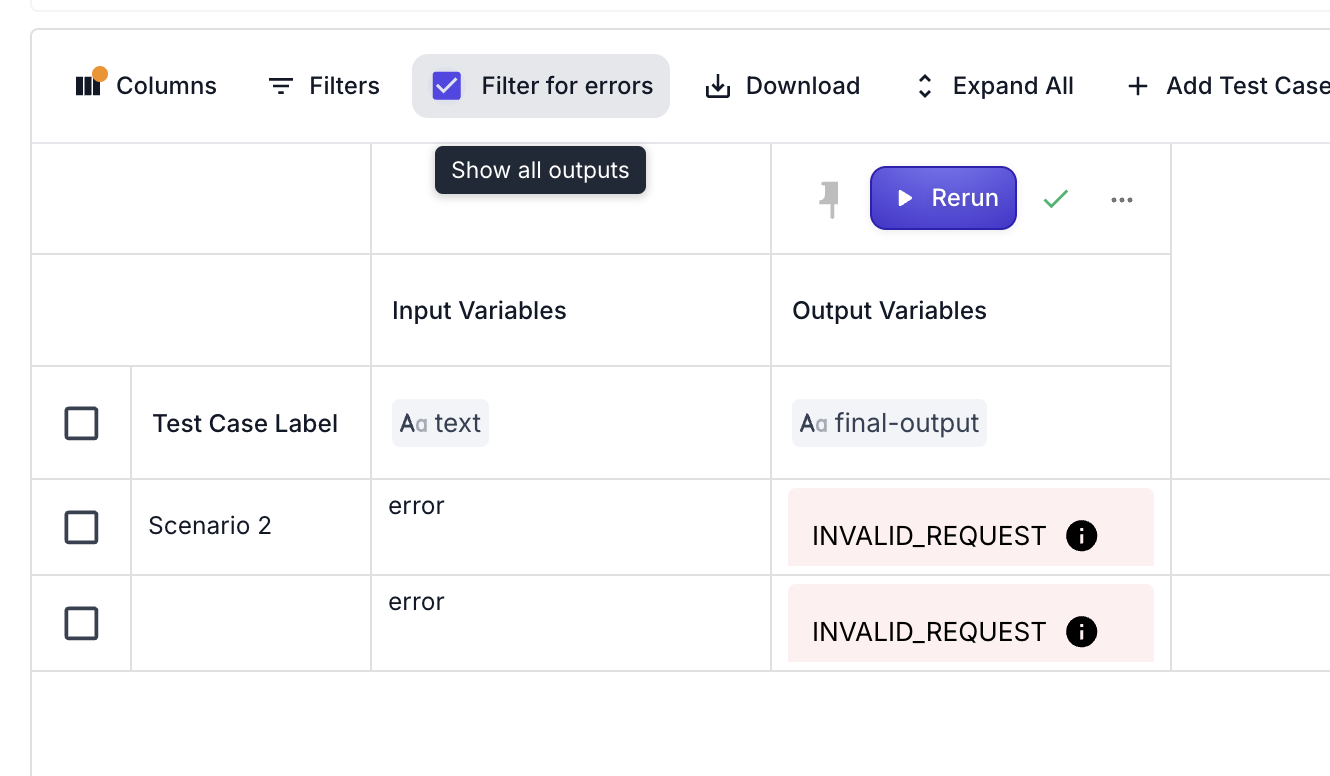
Filtering and Re-running Errored Test Cases
When working with large evaluation reports, you may encounter provider rate limits or want to focus only on failed test cases. Vellum provides a feature to filter and select errored test cases in evaluation reports, allowing you to re-run only the failed tests.
To use this feature:
- After running a Test Suite, navigate to the evaluation report
- Look for the filter option that allows you to show only errored test cases
- Select the failed test cases you want to re-run
- Click the “Run Selected” button to execute only those test cases
This feature is particularly useful when:
- You’re working with large test suites and hit provider rate limits
- You want to focus on fixing specific failures without re-running successful tests
- You’re iteratively improving your prompt or workflow to address specific error cases
Uploading Test Cases
To help you migrate your Test Cases into Vellum, we provide two methods for bulk Test Case uploads.
Via CSV
Under the “Test Cases” tab on the “Test Suite Details” page, there is a blue “Upload Test Cases” button. Clicking that button will open a modal that allows you to bulk upload test cases via a CSV file.
Via API
To upload test cases via API, check out the Test Cases API documentation.
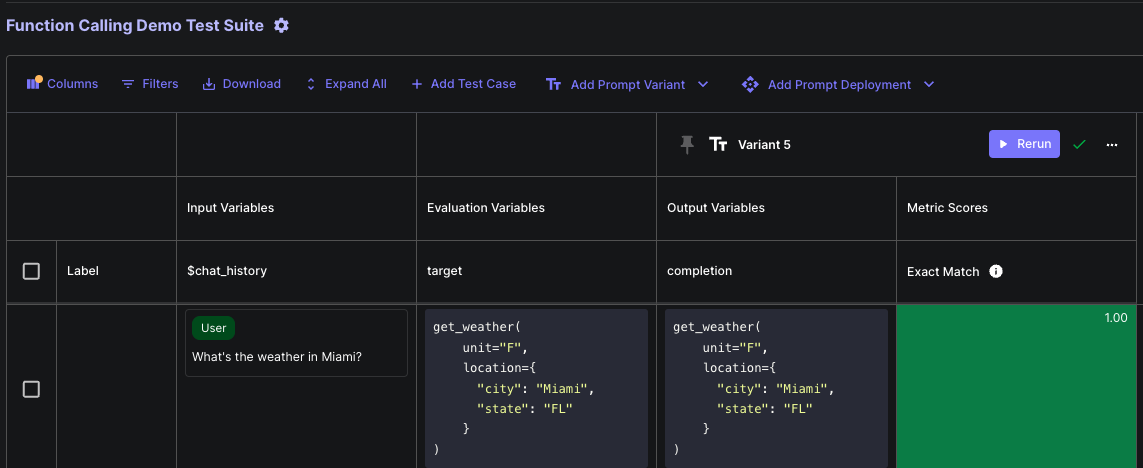
Function Calling
Prompts can output different modalities, which at Vellum we call input and output types. One increasingly popular output type for models if function/tool calling. You can use Vellum Test Suites to ensure that your model is producing the correct function call based on any given combination of inputs.
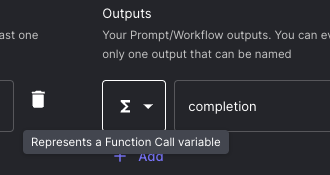
First, you will want to edit the Output Variable type of the test suite to the “Function Call” type:
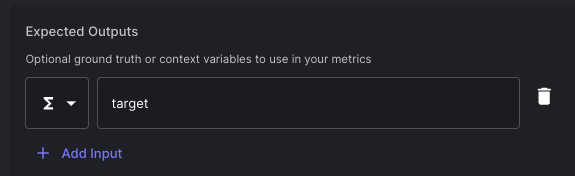
Next, define the Expected Output type to be of type “Function Call” too:
You can then use any Metric to help ensure that your prompt is outputting function calls that perform well across your test cases! Here’s an example of a test suite using Exact Match as the Metric:
Testing Workflows
Just like Prompts, Workflows can be tested too. The key difference Workflow Test Suites have is that Workflows may have multiple outputs. You may choose to test some of them, or all of them.
Workflow Test Suites can be run from the “Evaluations” tab in the Workflow Builder. It works very similarly as testing prompts, but you can create new test cases inline.
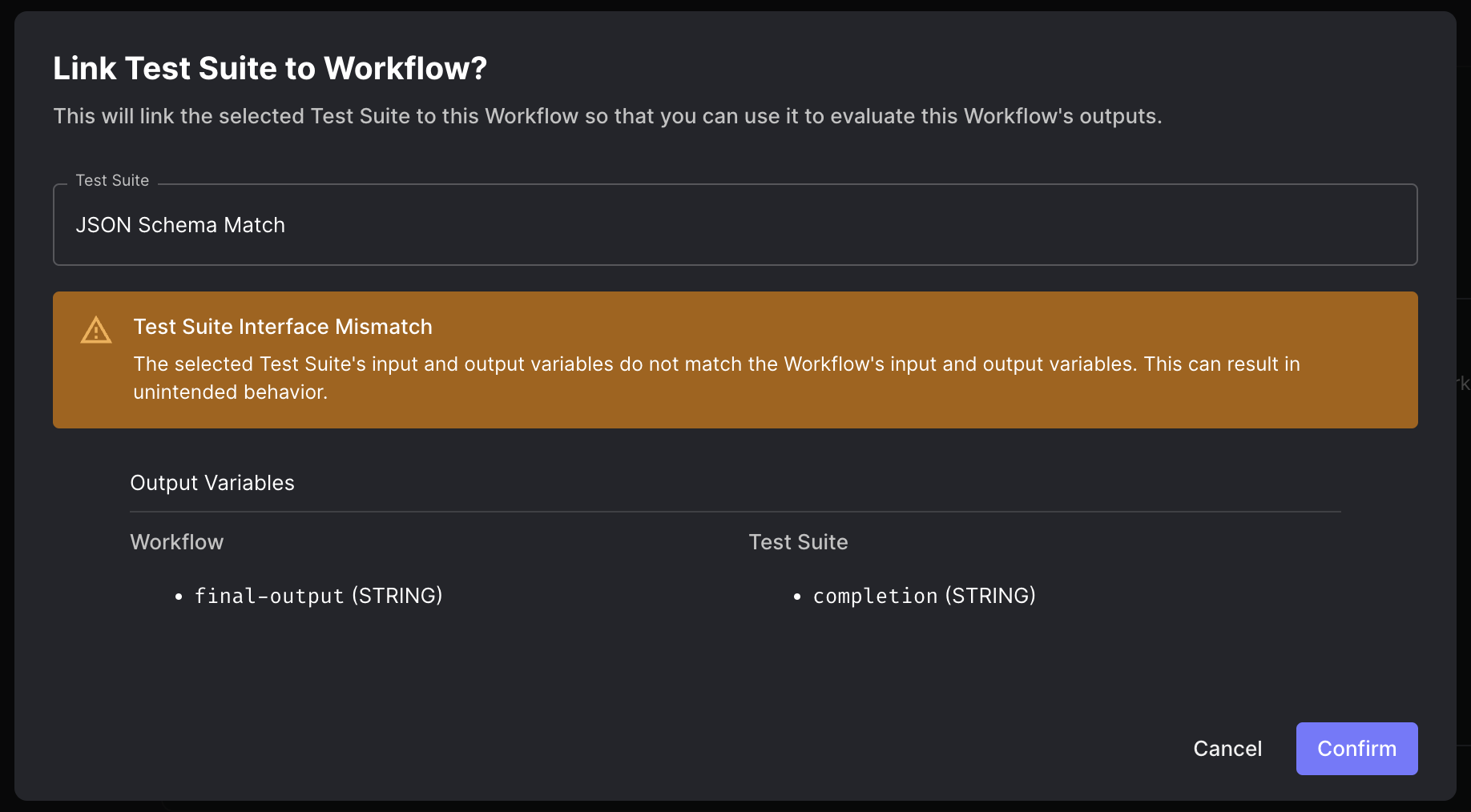
One common pitfall is trying to attach a Test Suite where the output variable is named completion
to a Workflow where the output variable is something else. You will receive a warning when this happens.
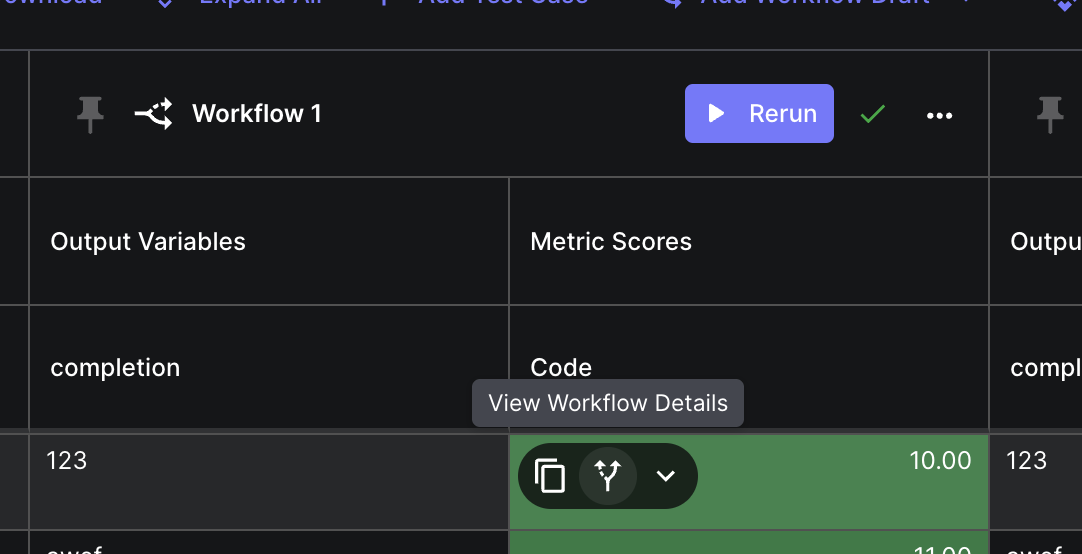
Viewing Workflow Test Case Entity’s Execution Details
To help you diagnose issues with workflows you can click on the “View Workflow Details” button located within a test case’s value cell to view the details.
Testing Functions External to Vellum
Not only can Vellum’s evaluation framework be used to test Prompts & Workflows hosted in Vellum, it can also be used to evaluate the outputs of arbitrary functions hosted externally to Vellum.
For example, you might test a prompt chain that lives in your codebase and that’s defined using another third party library. This can be particularly useful if you want to incrementally migrate to Vellum Prompts/Workflows, but ensure that the outputs remain consistent.
For a detailed example of how to use Vellum’s evaluation framework to test external functions, see the python example here