Prompt Caching
Prompt Caching is a powerful feature that allows you to reduce both the cost and latency of your LLM calls by caching frequently used portions of your prompts. This page explains how Prompt Caching works, which models support it, and how to implement it effectively in Vellum.
What is Prompt Caching?
Prompt Caching is a feature provided by model providers (currently Anthropic and OpenAI) that allows for caching frequently used portions of prompts. When enabled:
- Reduced Costs: Cached tokens are typically around 50% cheaper than non-cached tokens
- Lower Latency: Cached prompts process significantly faster, improving response times
- Preserved Context: The model maintains full context of the cached content without re-processing it
Prompt Caching is performed by the model providers themselves (Anthropic and OpenAI), not by Vellum. Vellum provides the interface to enable and configure caching for supported models.
How to Enable Prompt Caching in Vellum
For Anthropic Models
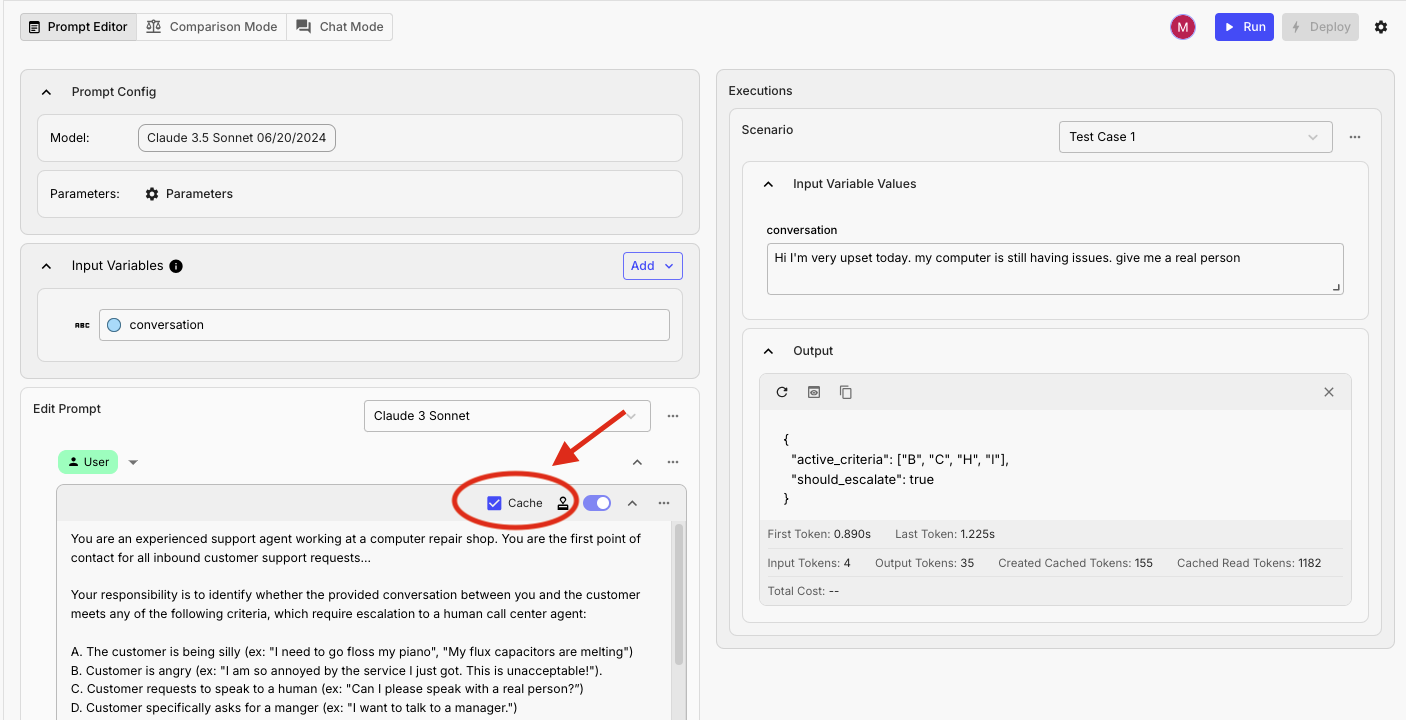
Anthropic allows you to explicitly define which parts of your Prompt should be cached using a special syntax. In Vellum, this is made simple with a UI toggle:
- Open your Prompt in the Prompt Editor
- Select a Prompt Block that contains content you want to cache
- Toggle the “Cache” option in the block settings
For OpenAI Models
OpenAI automatically handles caching without requiring explicit markup. When you use the same Prompt content repeatedly, OpenAI will automatically cache it to improve performance and reduce costs.
Best Practices for Prompt Caching
What to Cache
For optimal results, cache:
- Static Content: Parts of your Prompt that don’t change between requests
- Large Context: Document content, instructions, or other large blocks of text
- Frequently Reused Content: Information that will be used across multiple requests
Even if content is technically “dynamic” but will be reused frequently (like a specific document or context), it’s still beneficial to cache it.
Example: Caching Document Context
A common pattern is to cache document content while keeping questions dynamic:

This approach allows you to ask multiple different questions about the same document without re-processing the document content each time.
Cache Expiration
Cached tokens usually expire within a few minutes, after which the model will need to process the full Prompt again. You will likely notice a brief increase in latency, and you will be charged for the full prompt.
Cache durations can vary by model provider, so be sure to check the documentation for the specific model you are using.
Monitoring Cache Performance
Vellum provides visibility into your cache performance through the Prompt Deployment Executions table:
- Navigate to your Prompt Deployment
- Go to the Executions tab
- Enable the cache-related columns from the column selector:
- Cache Read Tokens: Tokens read from cache
- Cache Creation Tokens: Tokens added to the cache

These metrics can help you analyze your cache hit rate and optimize your prompting strategy to maximize cost savings.
Implementation Examples
RAG Application with Cached Context
For a RAG (Retrieval Augmented Generation) application, you can cache the retrieved document chunks while keeping the user query dynamic:
Multi-turn Conversations with Cached Instructions
For chatbots with complex instructions, cache the system instructions while keeping the conversation history dynamic:
Conclusion
Prompt Caching is a powerful optimization technique that can significantly reduce both the cost and latency of your LLM calls. By strategically caching static or frequently reused content, you can build more efficient and responsive AI applications while reducing your operational costs.