Prompt Engineering
Prompts are the “instructions” that you give to Large Language Models (LLMs) to generate a response. If you’ve used ChatGPT, then you’ve actually already interacted with an LLM that was provided with a Prompt on how it should respond in a helpful, polite manner!
When building your own AI-powered application, you’ll very likely need to come up with your own Prompts. Furthermore, Prompts are rarely static strings. Instead, most Prompts are “templates” with dynamic sections whose contents are determined at runtime. For example, you might need to include information about the user that’s interacting with your application, some relevant section of a knowledge base, etc.
Vellum encourages the development of dynamic prompts by providing a powerful prompt syntax that supports variable substitution, jinja templating, and function calling. At a high level, you define “Input Variables” and reference those variables in your Prompt. You can experiment with different values for these variables via “Scenarios” to determine what the LLM’s output would be.
You can reference input variables in your Prompt in one of two ways using different types of “blocks.”
- Rich Text Blocks: Great for most use-cases where a simple variable substitution is needed.
Begin type
{{or/to get a dropdown of available variables. - Jinja Blocks: Used for more complex use-cases where you need the power of Jinja templating syntax to perform conditional logic, loops, etc.
Rich Text Blocks
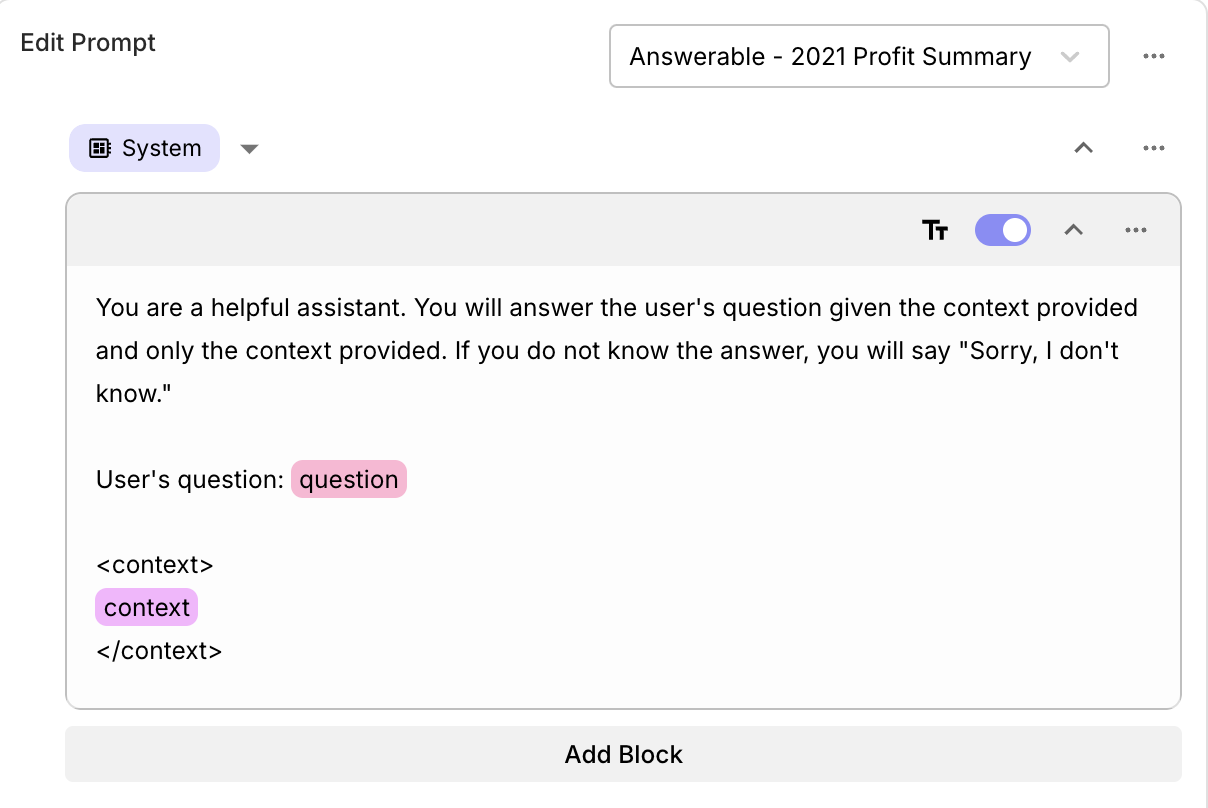
Most of the time, you’ll use Rich Text blocks for simple variable substitution.
These blocks are easy to use and are great for most use-cases. You can reference
variables by typing {{ or / to get a dropdown of available variables.
Here’s an example of a Rich Text block:
Jinja Blocks
Jinja is a powerful templating syntax useful for dynamic content. In its most basic form, you might use it to reference Prompt Variables. However, if all you need is variable substitution, consider using a Rich Text block instead.
Below are the most common things you’re likely to want to do, but you can find jinja’s complete documentation here.
Variables
Reference variables using double-curly-brackets. For example,
Note that all prompt variables are treated as strings!
Conditionals
Perform conditional logic based on your input variables using if/else statements
Comments
You can use jinja to leave comments in your prompt that don’t use up any tokens when compiled and sent to the LLM. For example,
JSON Inputs
Vellum supports JSON input variables. When you supply a JSON variable, you can use this trick to access specific key/value pairs.
For example, say you have a variable called traits whose value in a Scenario looked like:
Then you can access “happy go lucky” by using a Jinja template block and referencing the JSON variable like so:
Casting Variable Types
Vellum currently treats all input variables to prompts as strings. However, you may use jinja filters to convert your variables to specific types and then use them accordingly. For example:
Blocks
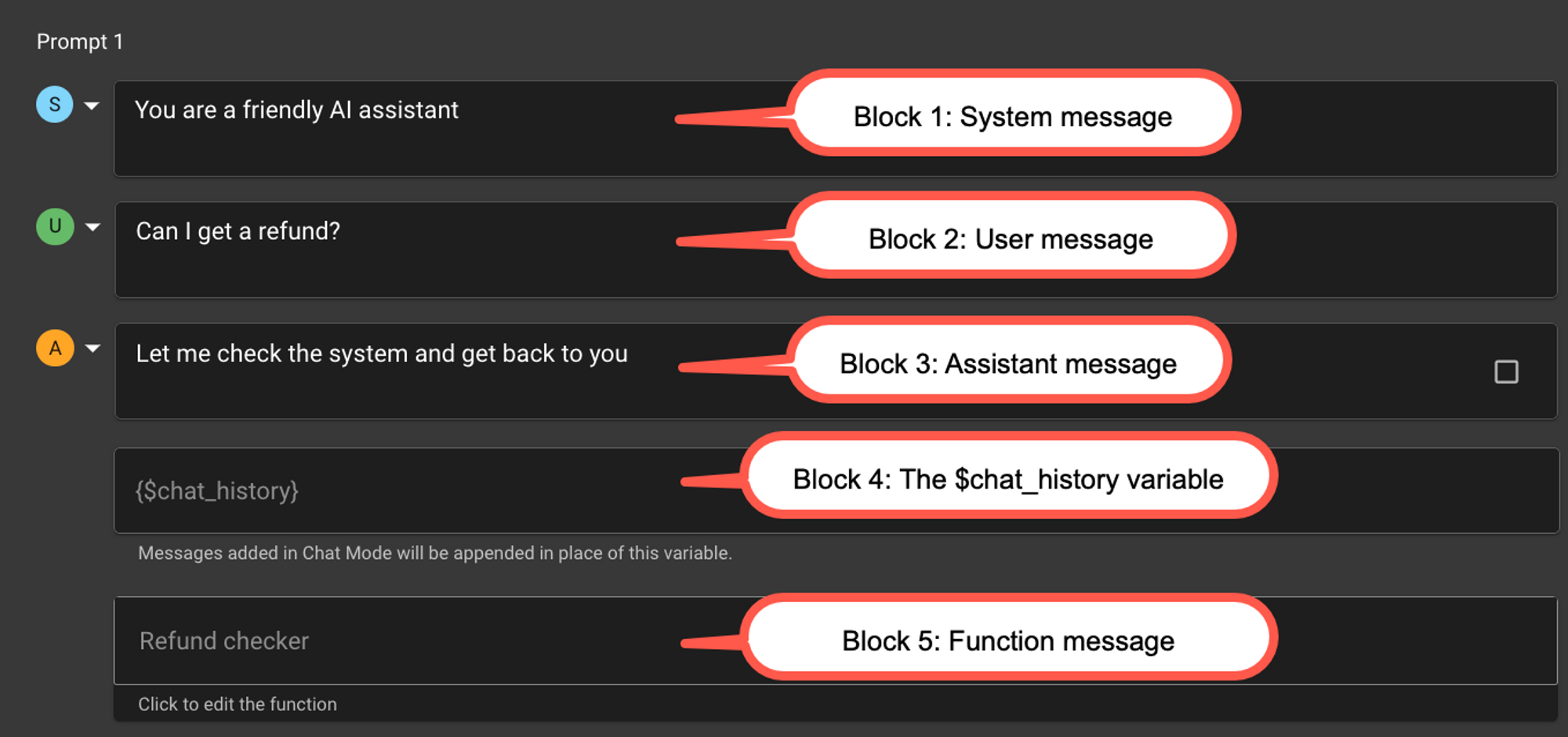
Vellum uses blocks to separate key pieces of a prompt, such as System/Assistant/User messages of a Chat model (e.g. gpt-3.5-turbo or claude-v1) or the special $chat_history variable.
Blocks are more noticeable when using a Chat model than when using a Text model.
Chat Model Example
Here’s what a sequence of blocks might look like for a Chat model
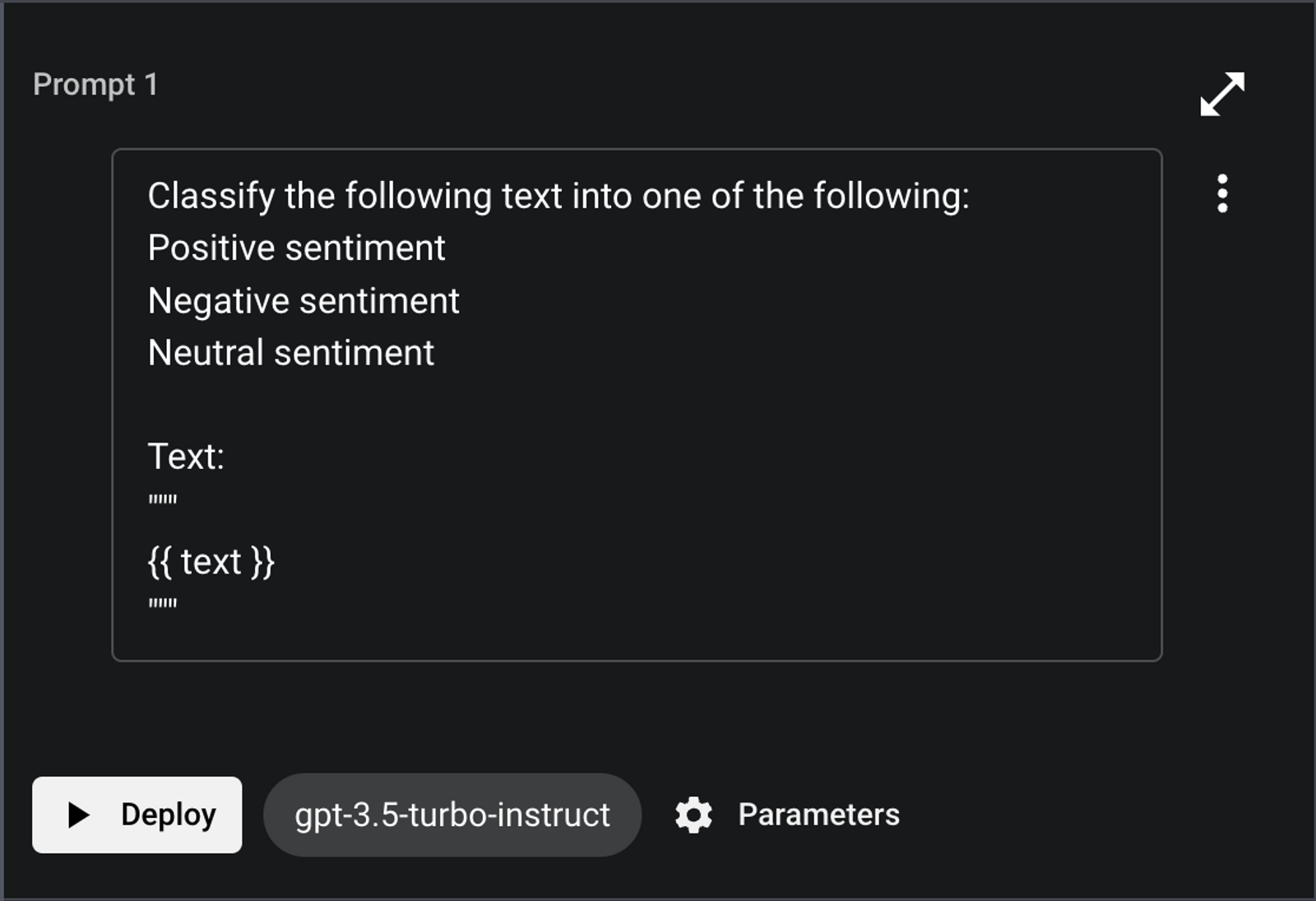
Text Model Example
Text models typically use a single block, which might look like this:
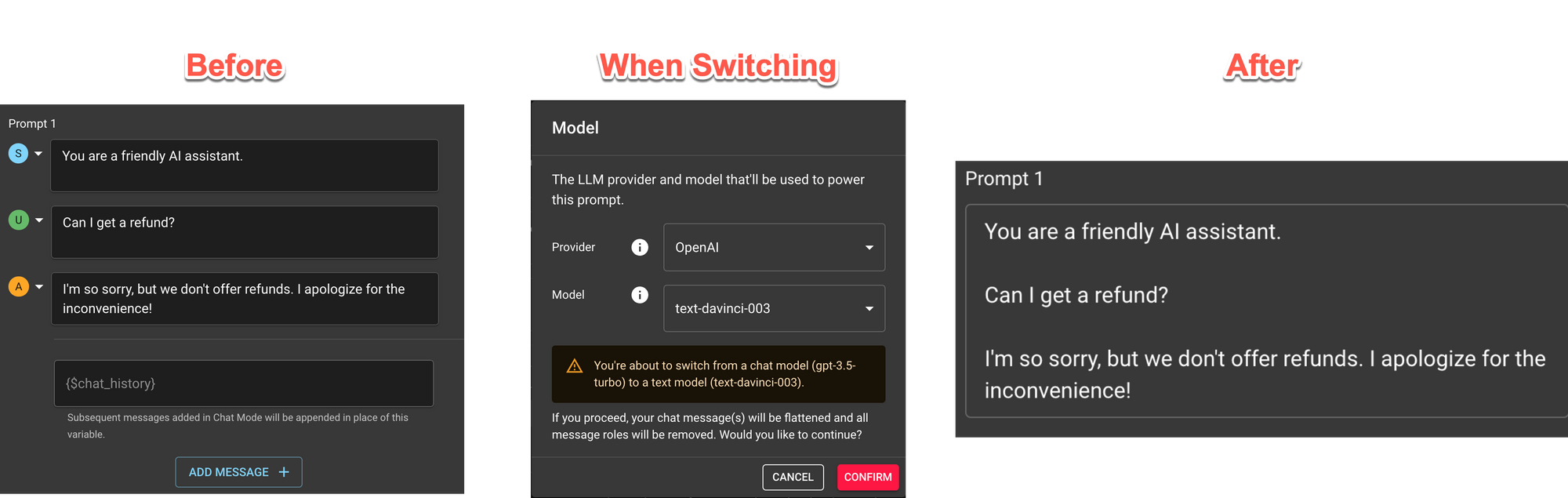
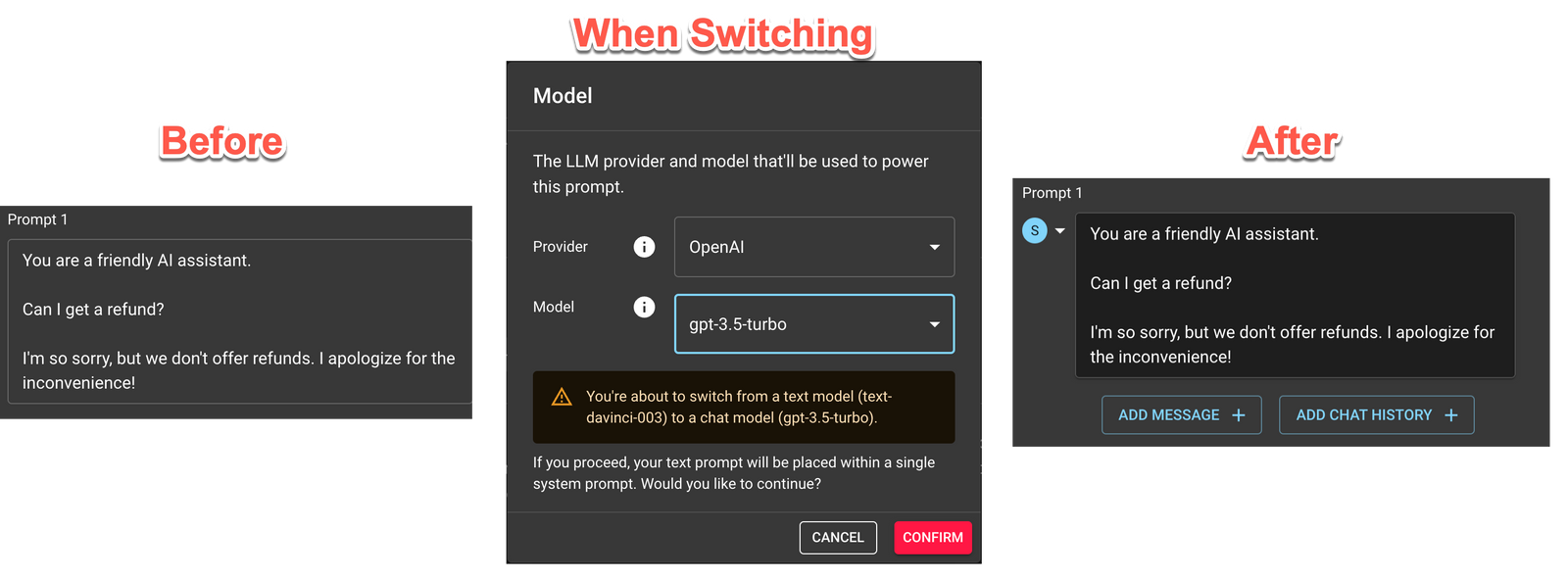
Switching from Chat ↔ Text Models
When switching from a Chat Model to a Text model, blocks are converted as best they can be.
Chat → Text
Here’s an example going from Chat to Text.
Text → Chat
Here’s an example going from Text to Chat.
Function Calling
Function Calling allows you to provide function definitions within your prompts that the model could use in deciding how to respond with each user prompt. It’s best to think of functions as a type of classifier prompt that pushes to model to respond with either:
- The name of one of those functions, with associated parameter values.
- A standard text response.
This definitive response from the model allows developers building LLM features into their applications to know when to call a function or when to return a message to the user. This removes the need to try parsing JSONs are other formats from the LLM text response, leading to more stable user experiences.
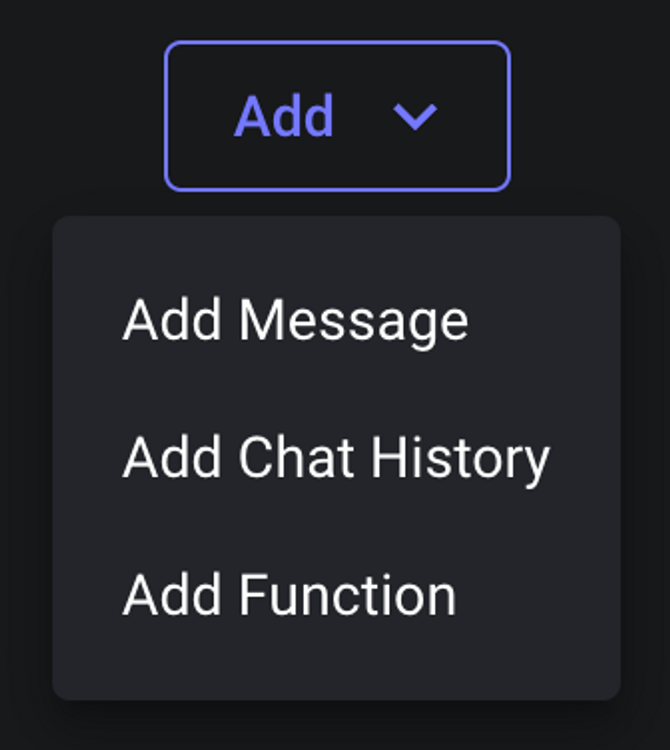
To define a function, you first need to choose a model that supports function calling and click the + Add → Function button at the bottom of your prompt:
Then, click the block that’s created and a modal will appear where you can start defining your function! There are three important sections to consider:
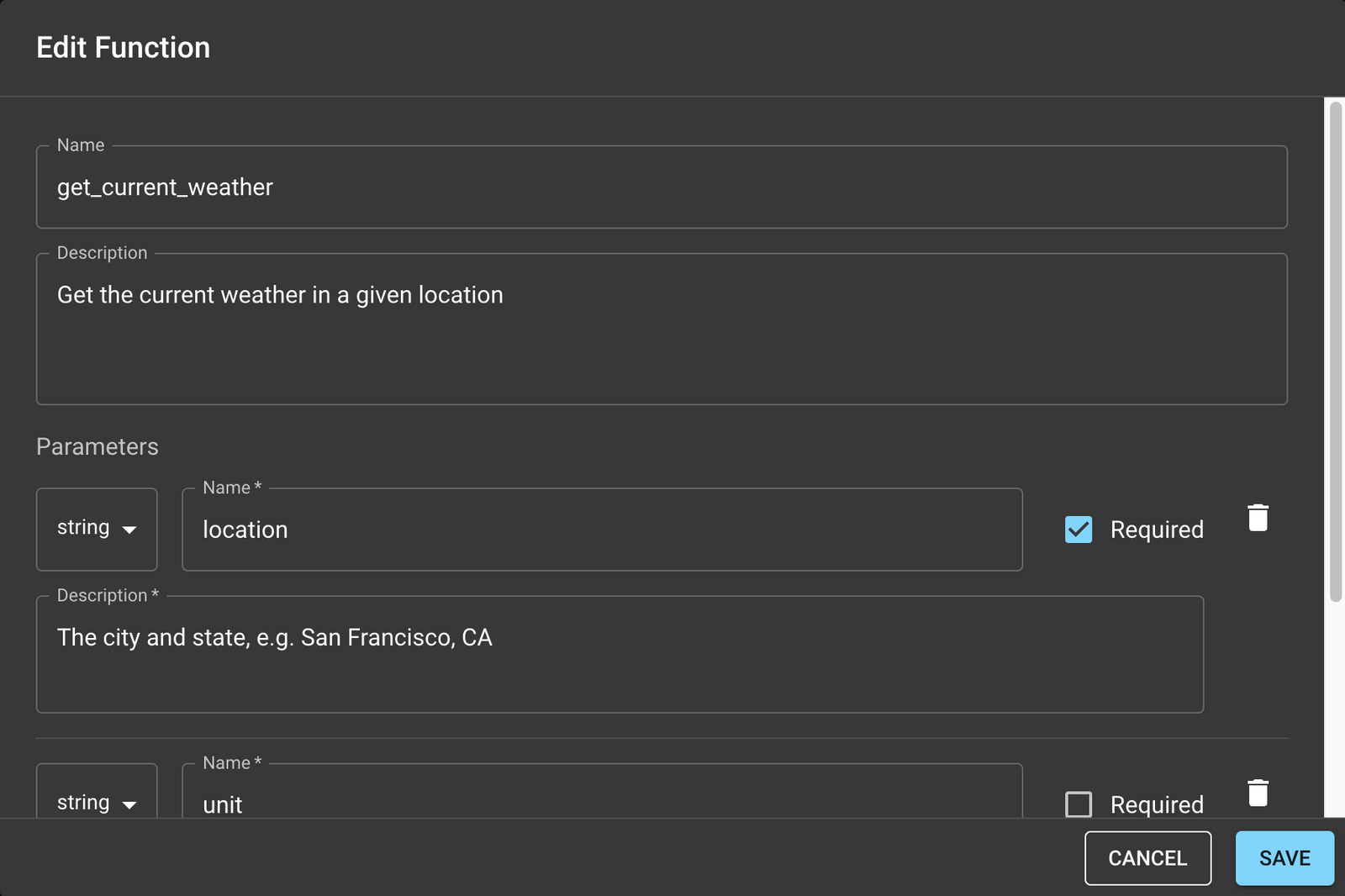
Name- This is a single identifier that the model will use to instruct you which function to call nextDescription- This is a natural language description of what your function does. This is the part most used by the model to decide which function to call and should be considered counting towards your token count.Parameters- The set of parameters your functions accept. Each parameter will also have aName,Description, &Typethat the model uses to decide what values the function should be called with.
When you then call the model with a prompt along with these function definitions, the model will then decide whether it makes sense to call one of the defined functions or return the standard text response. If it decides to call a defined function, the response will be a JSON directing which function to call and with which parameter values:
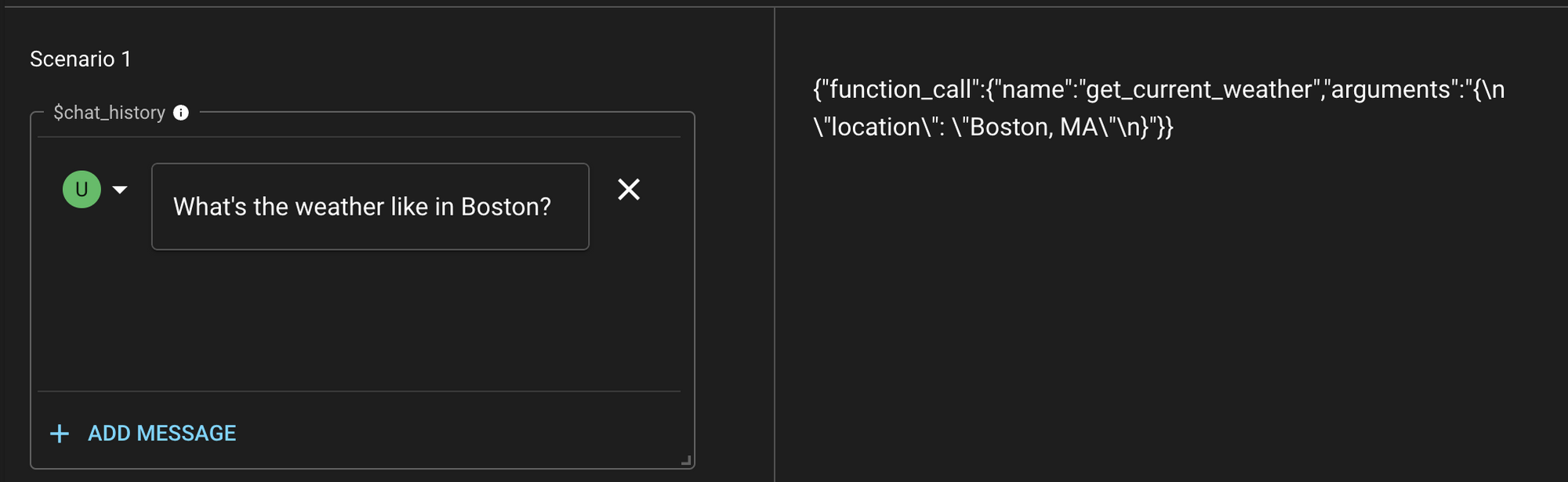
Notice that in this example, the model is directing us to call the get_current_weather function with the location parameter set to Boston, MA. At this point, it is up to the app developer to actually invoke the function - the model itself does not have access to the execution logic. These functions should represent public or private APIs that the app developer supports and could invoke once instructed by the model.
Once the function is called and a response is observed, the response should be fed back to the LLM as a function message so that the model knows what was the outcome of calling that function. The model will then be able to use the response of that function when deciding how to respond next in order to satisfy the original prompt.
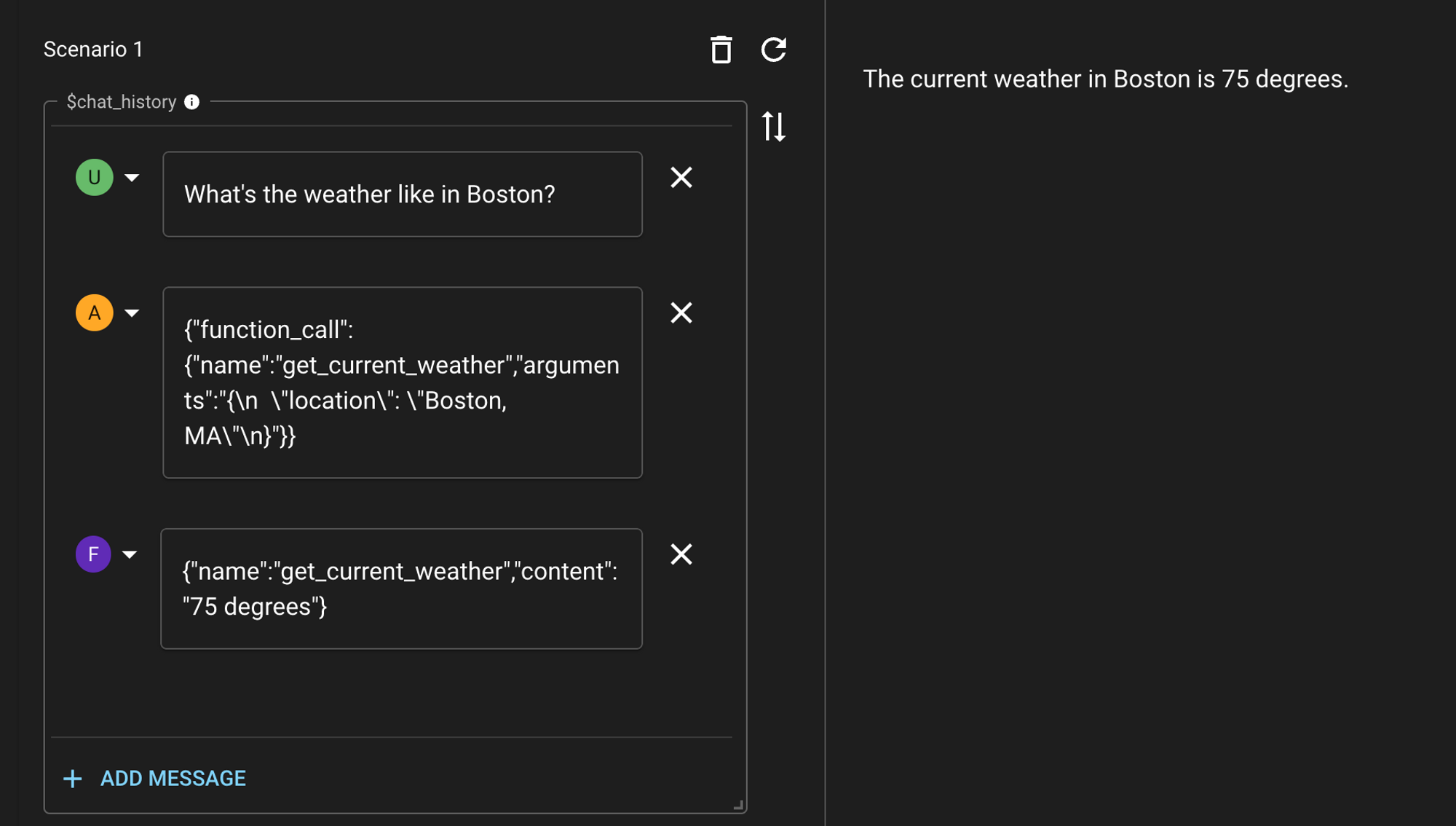
Notice that we need to specify the original response from the model as an assistant message, before following up with a function message. The final output from the model then represents its understanding of the user’s prompt and the output of the function it had access to.
Once you have reached this point, you’ll have everything you’ll need to add functions to models! Function calling is best used for incorporating the following types of data into your prompts:
- Runtime or recent data - New data that has become available that the developer’s APIs have access to but the model was not trained on
- Proprietary data - Data the developer has collected that is specialized to their business proposition that gives their application a comparative advantage
- Weighted data - Data that the model already has been trained on but that the developer would like to re-prioritize based on some special insights that could be inferred from their API
Previewing Compiled Prompts
Given the powerful and dynamic nature of Vellum’s prompt syntax, you may want to see what the final, compiled payload sent to the model provider after all variable substitutions and jinja templating is applied. You can do this in the Playground UI like so:
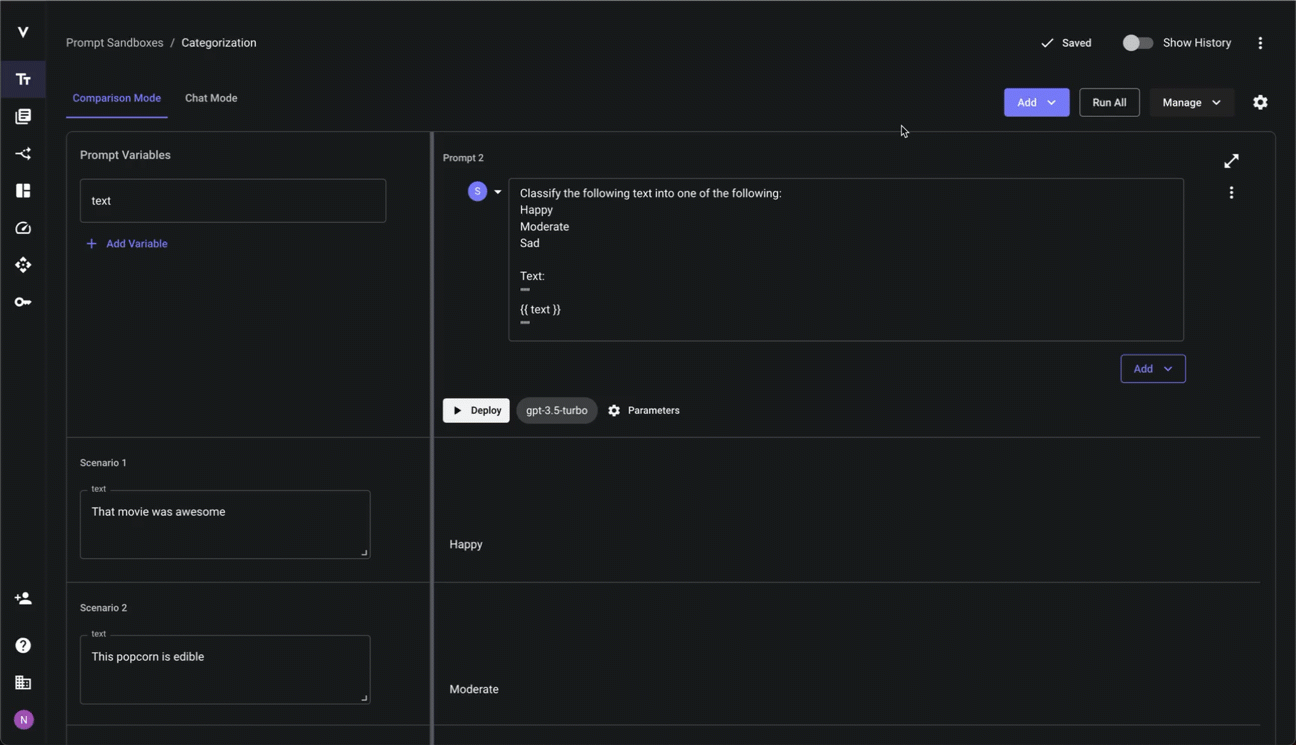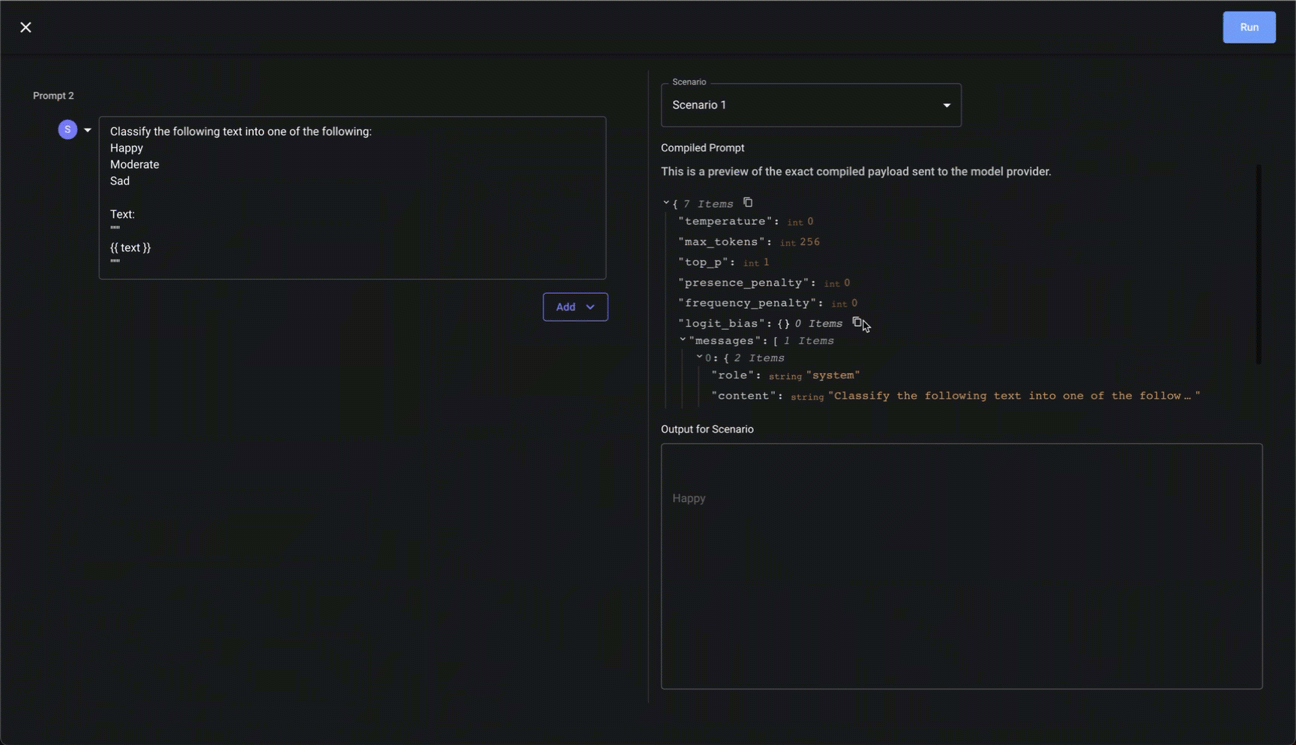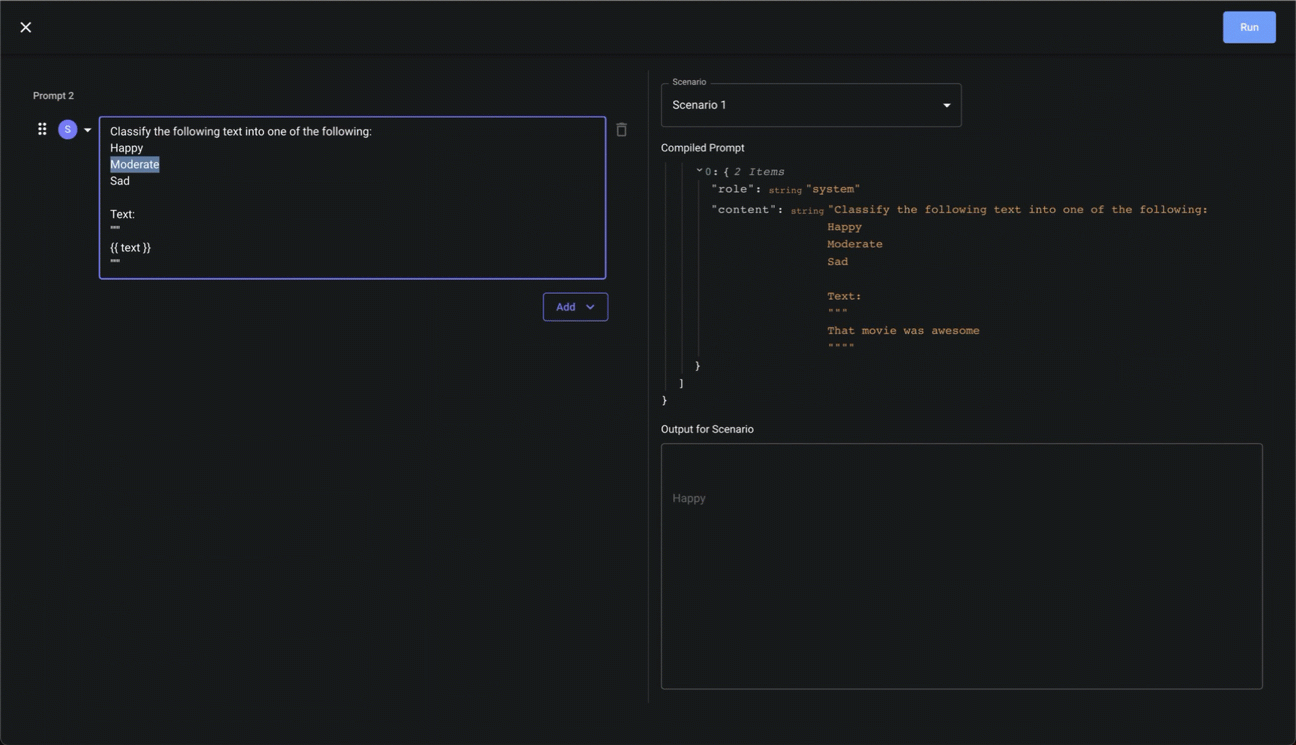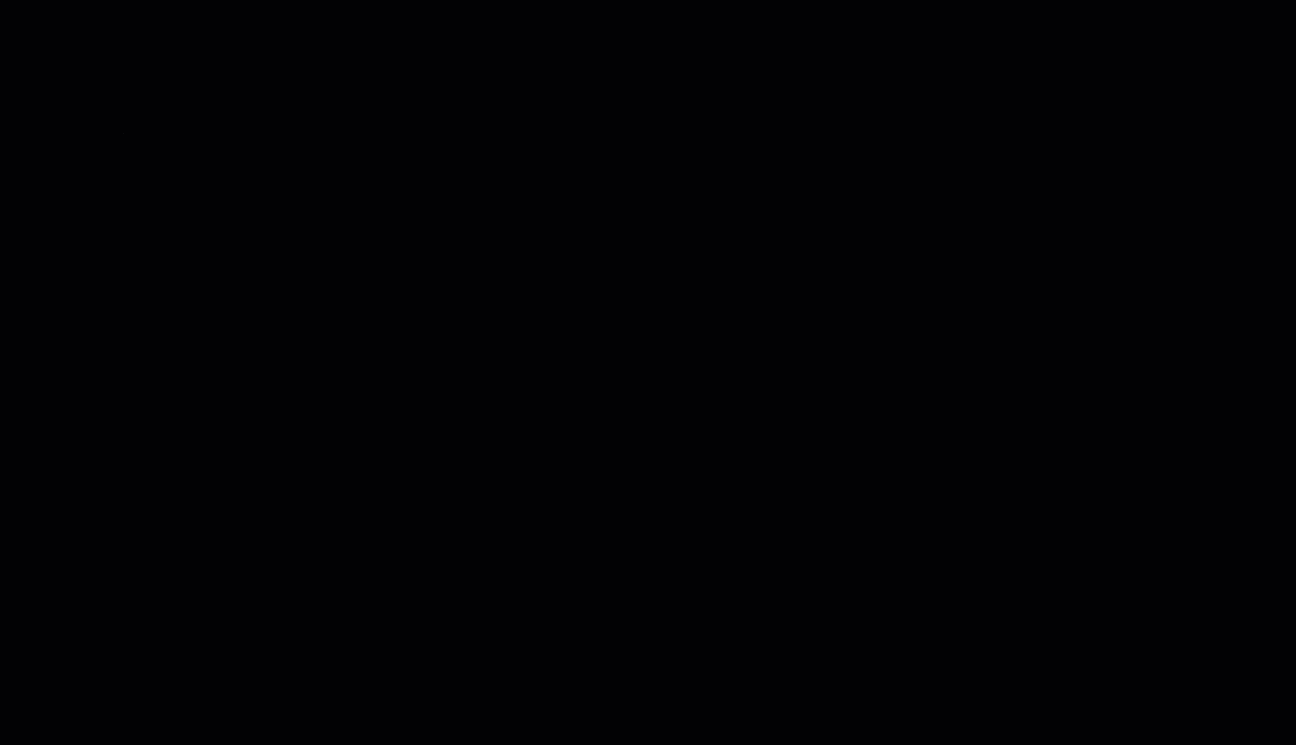
Viewing Prompt Usage
You can view how much token, character or compute time usage your prompts are costing you by enabling the “Track Usage” toggle in your Prompt Sandbox’s settings.
![]()