Input Images and Documents in Prompts and Workflows
Leverage the power of multimodal models to process both natural language and files within your LLM-applications using Vellum.
Vellum supports multimodal inputs for supported models from OpenAI, Anthropic, Google, Meta, and more via API and in the Vellum UI.
Read on to get started!
Using Images in the UI
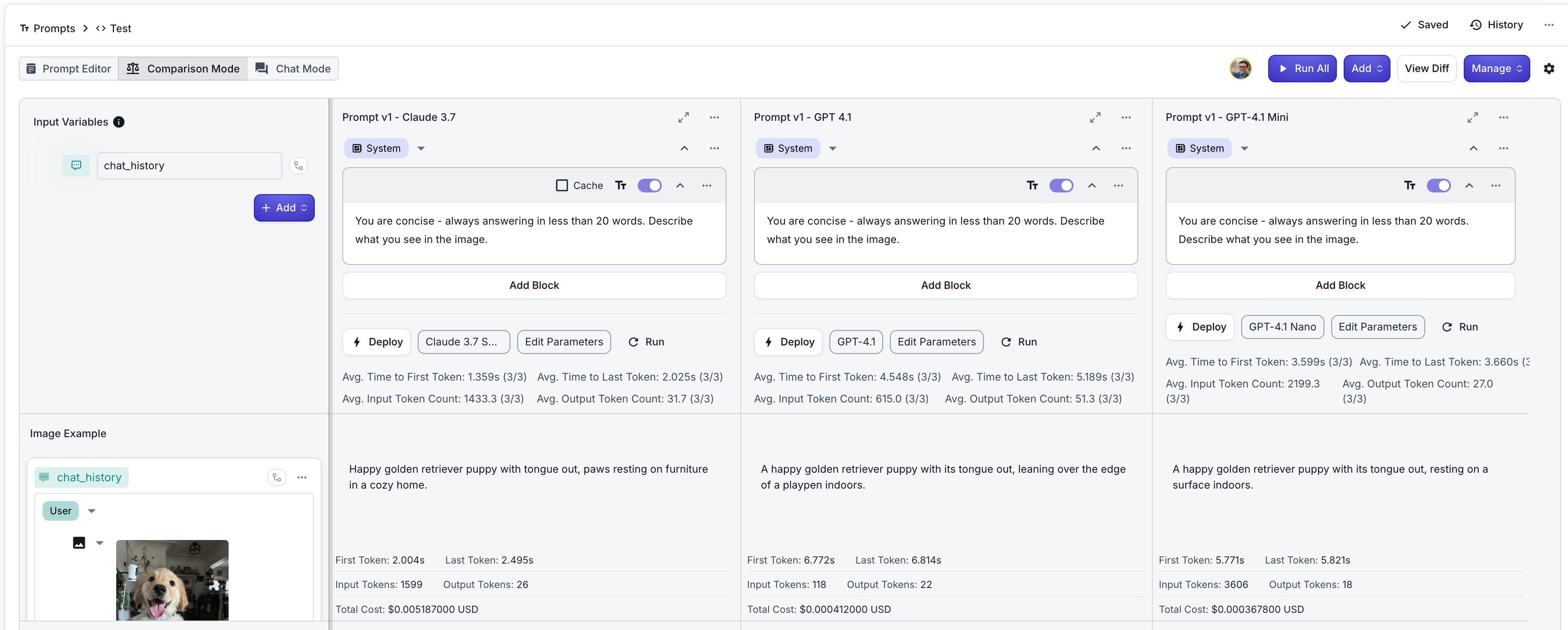
Vellum supports images as inputs to both your Prompts and Workflows. In either Sandbox, you can add images inside of scenario Chat History messages.
Begin by selecting a model that supports images in your Prompt. In Workflows, you can set the model within a Prompt Node. Before you do, you’ll want to add a Chat History variable as an input to your Workflow.
Next, add a Chat History block and some messages to your template so you can drag images within them.
Here’s how to do it:
- In the Prompt Sandbox, add a Chat History input variable by adding a new variable of type “Chat History”. This will allow you to drag and drop PDF files directly into Content Blocks.
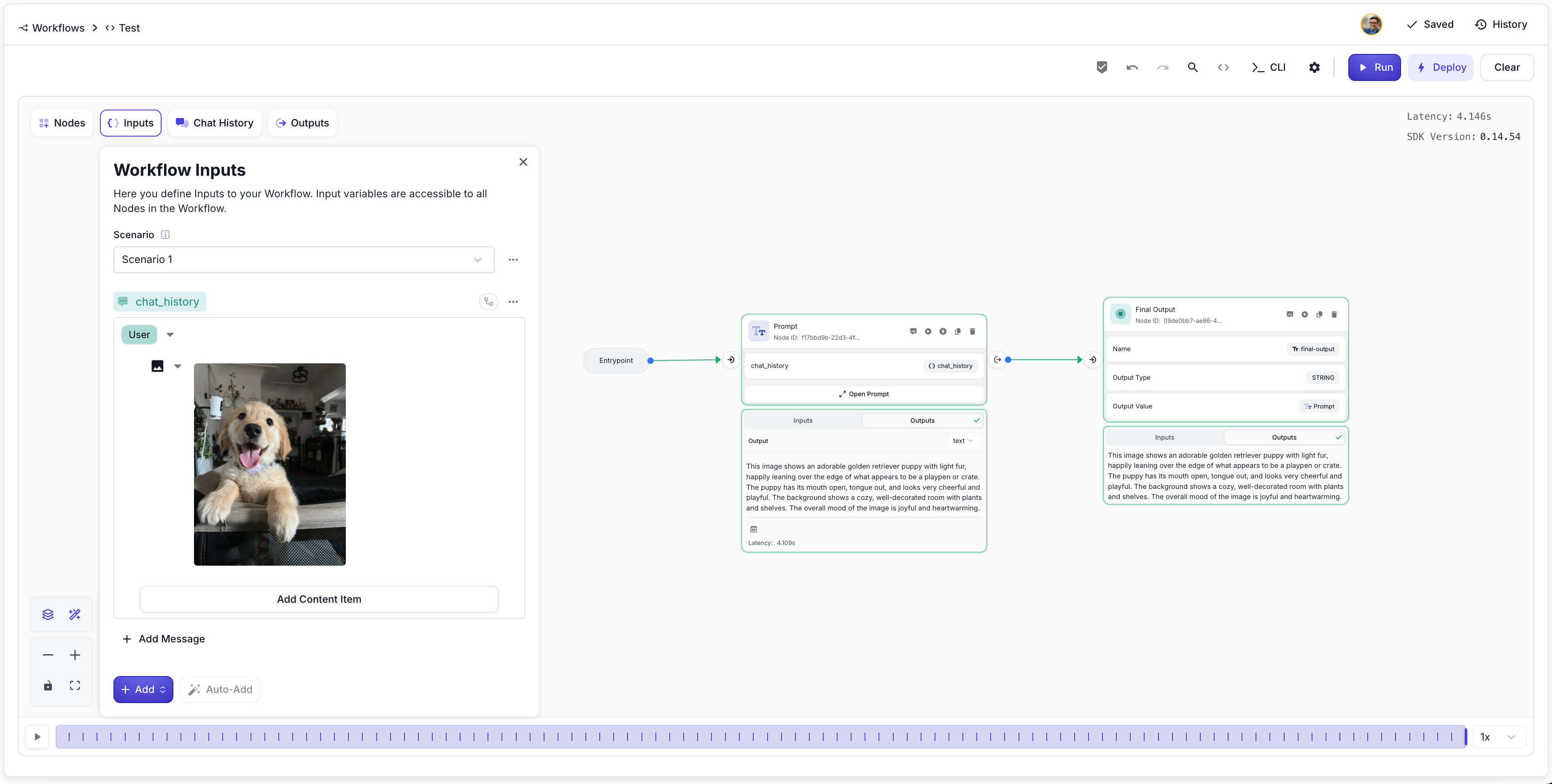
- In the Workflow Sandbox, add a Chat History input variable by adding a new variable of type “Chat History”. This will allow you to drag and drop PDF files directly into Content Blocks.
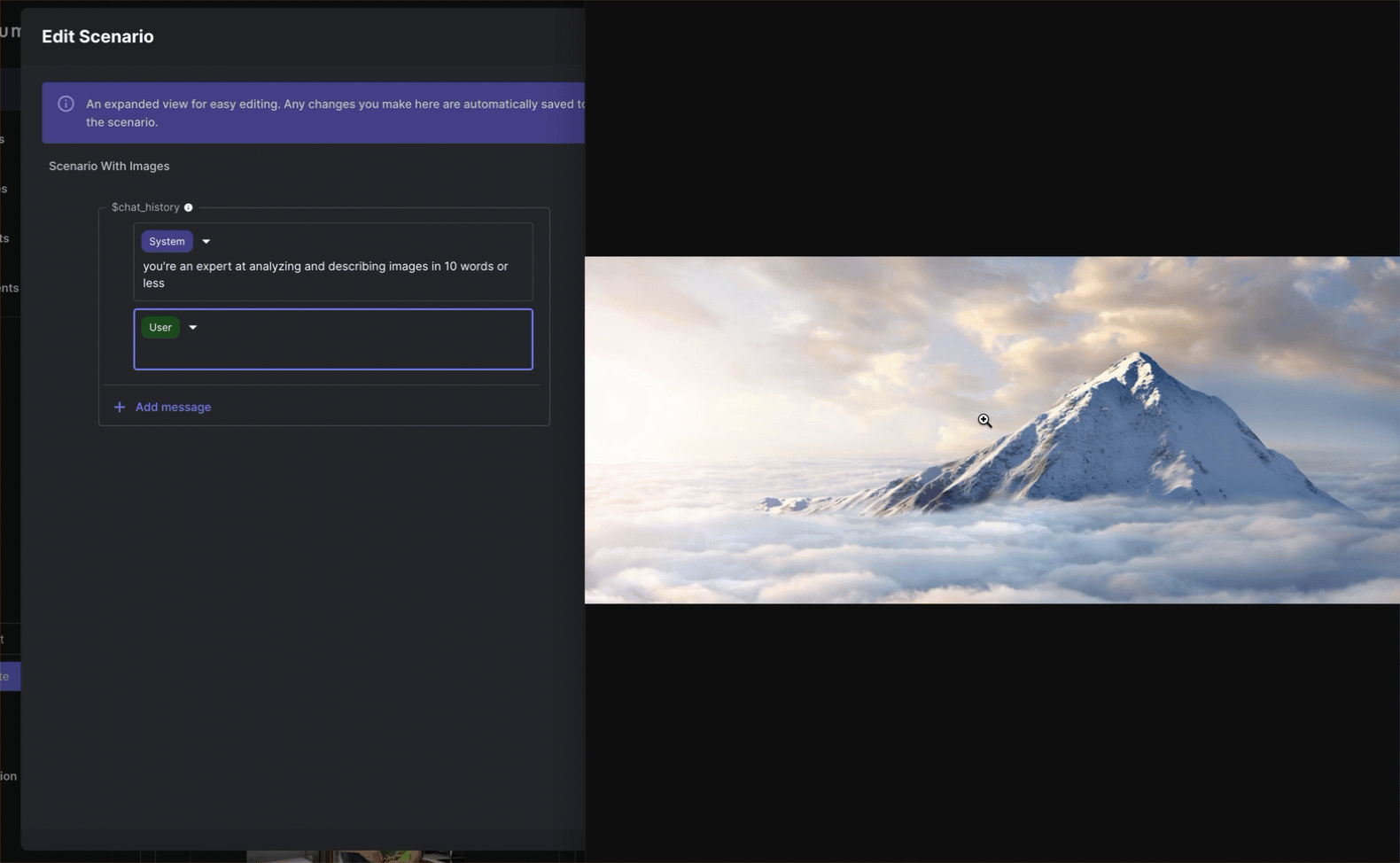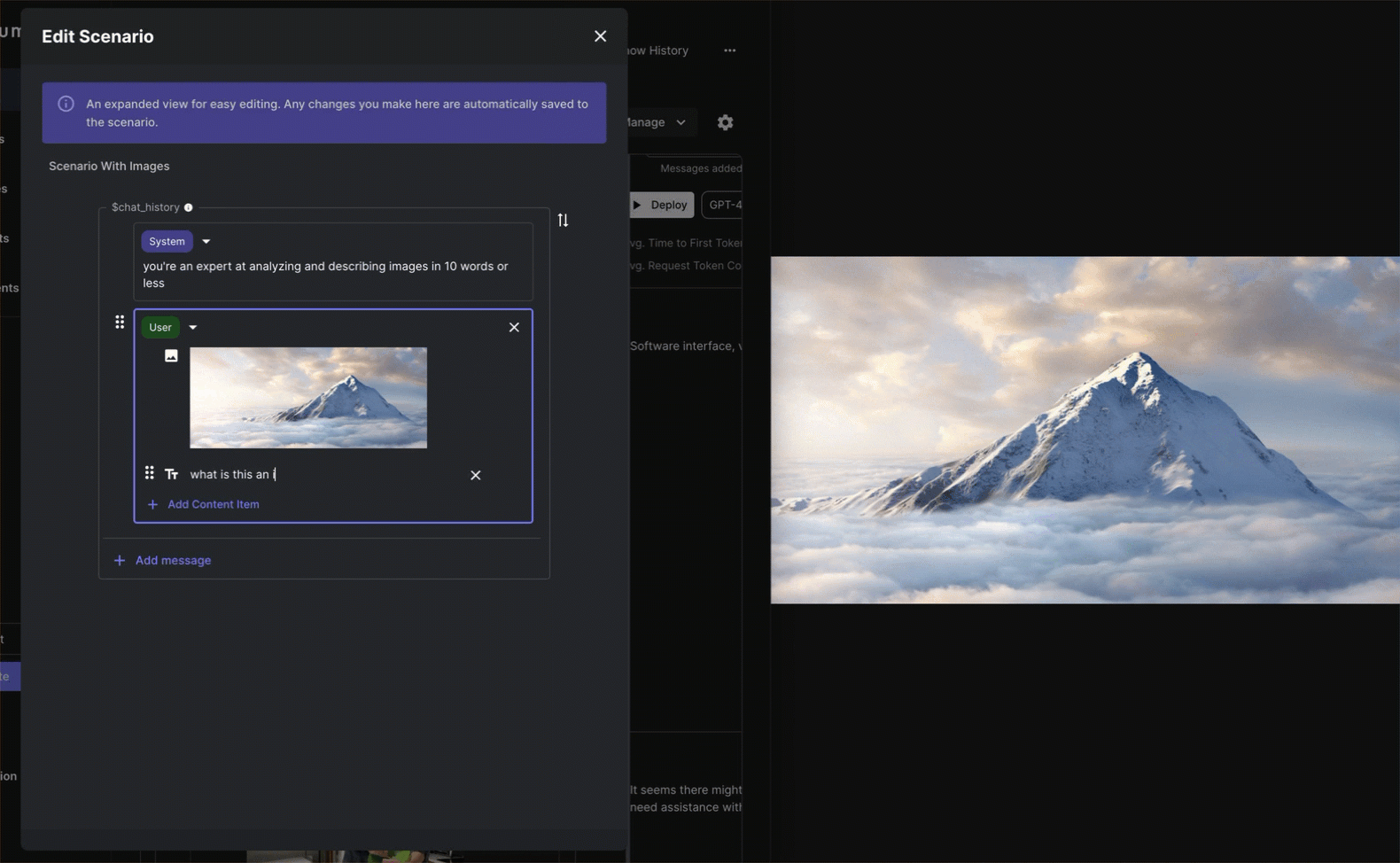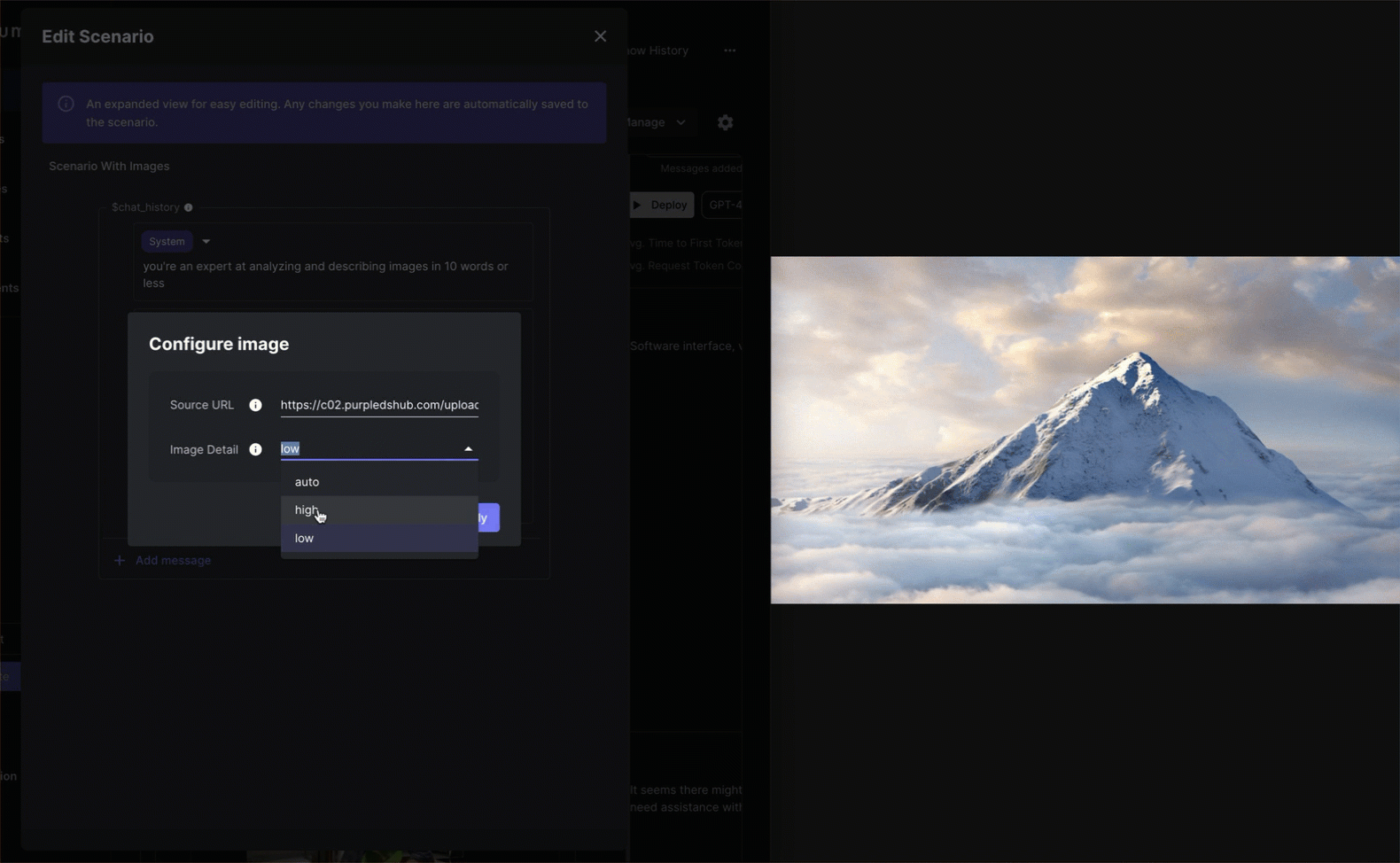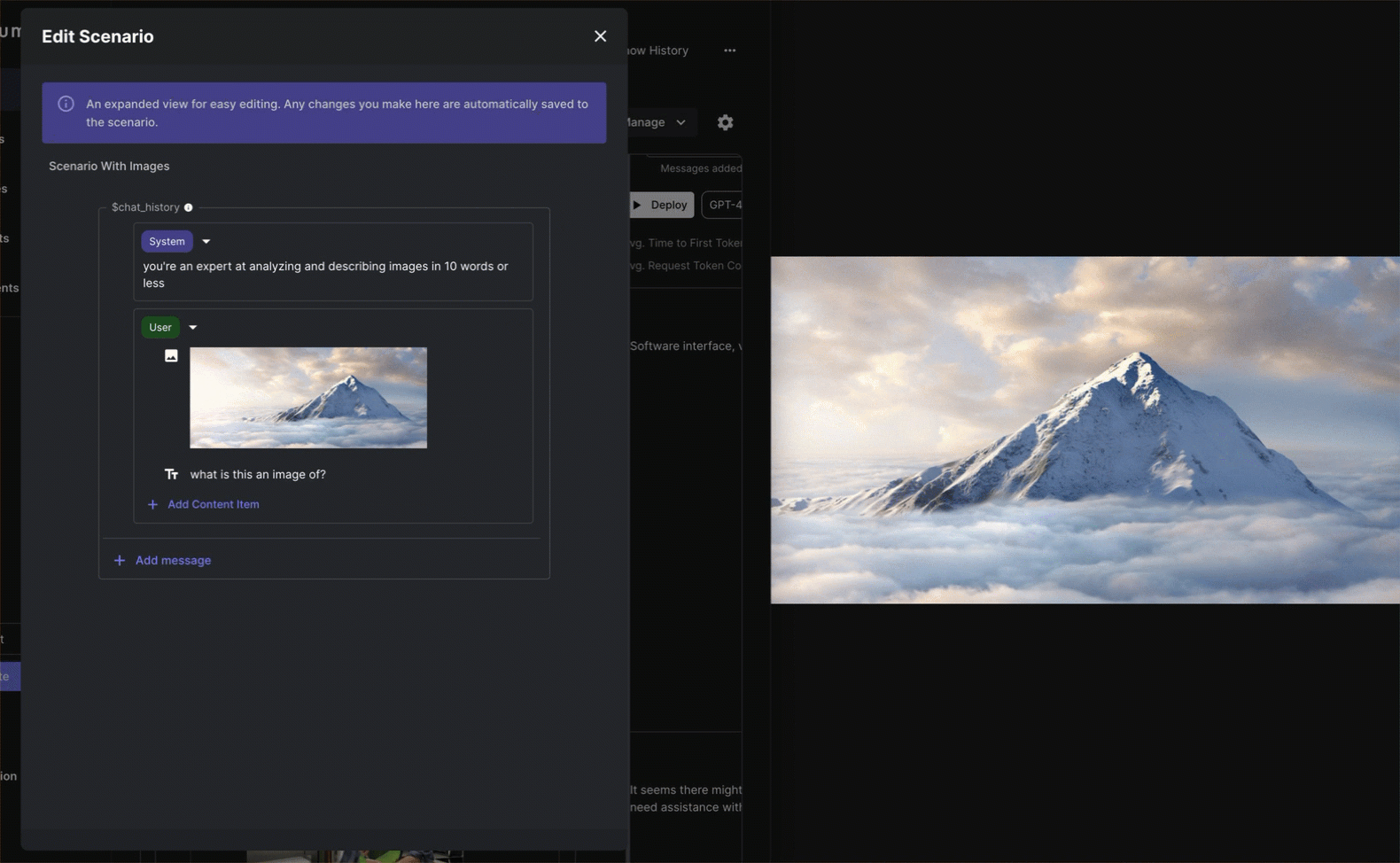
Now you’re ready to add images! Drag and drop a valid image into a Chat History message block. This converts the Chat Message into a draggable array that can be easily re-ordered and can contain multiple image and/or text items.
Valid image URLs: Images must have their absolute path including the image filetype in their URL and must be publicly visible (example: https://storage.googleapis.com/vellum-public/help-docs/release-tags-on-deploy.png)

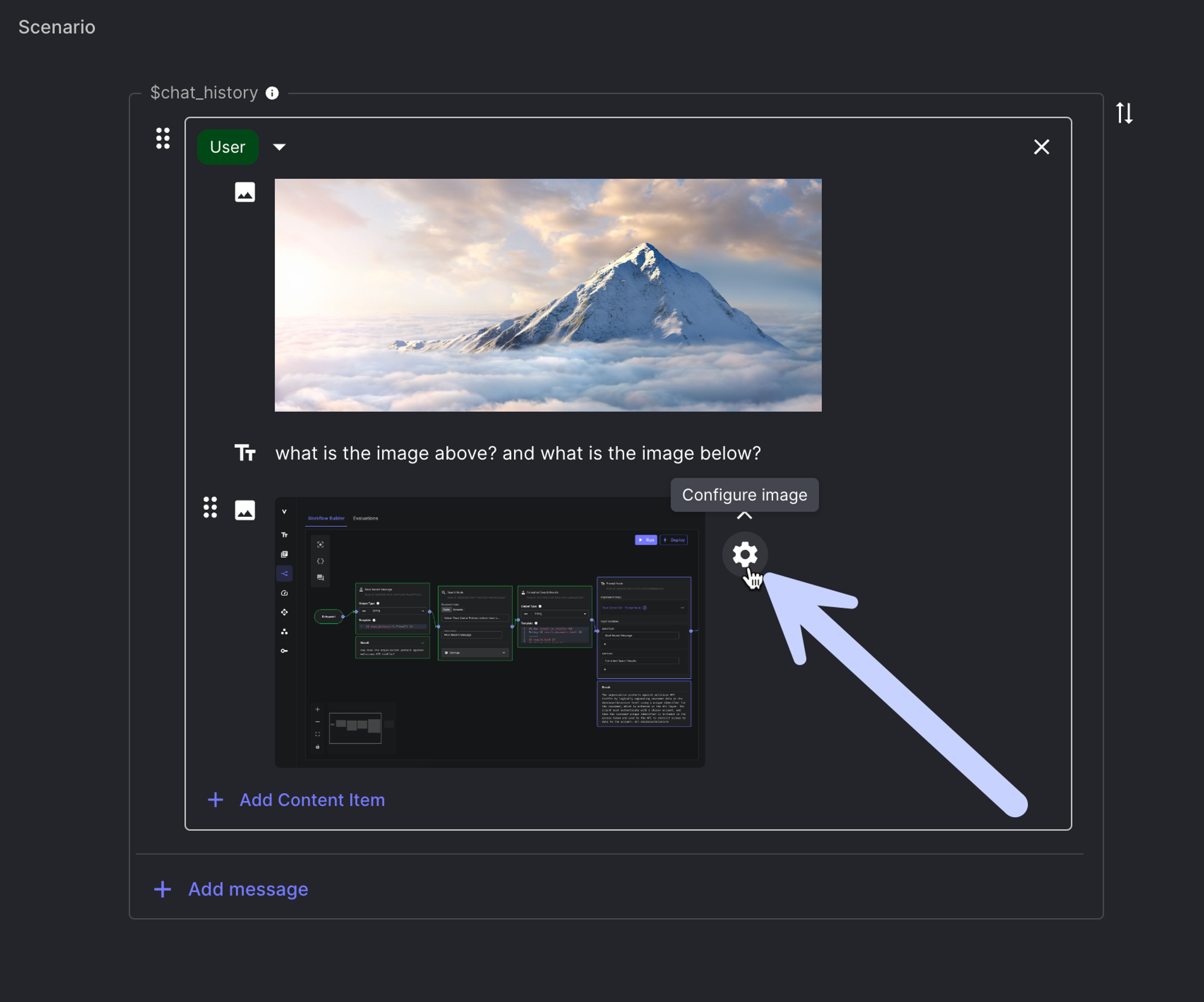
Once you’ve added in your image, you can configure its settings by clicking the small gear icon to the right of the image. Here you’ll be able to adjust things like the Image Detail which can have a big impact on token usage (more on that below).
You can also switch out an image you’ve dragged in for a new one by updating the image URL in the settings.
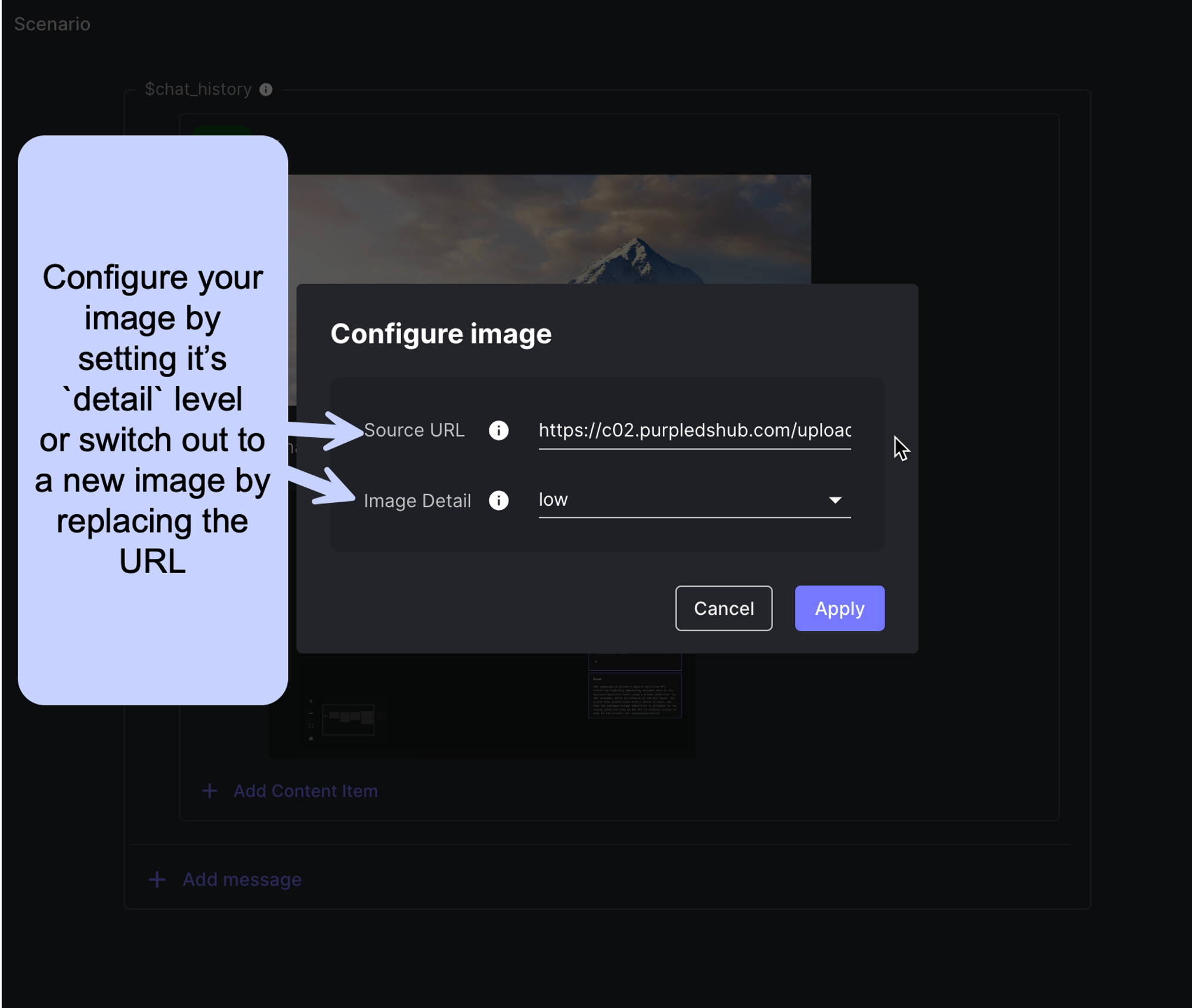
Image Specifications
Here are some important model specifications for OpenAI vision models to keep in mind as you’re incorporating images into your Prompts and Workflows:
-
Number of Images: No set limit
There is no fixed number here but token and image size restrictions still apply to determine the number of images that can be sent
-
Image Size: Less than 32MB
For prompts and workflows with multiple images, the combined image size should not exceed this limit
-
Supported Image Formats:
- JPEG (.jpeg / .jpg)
- PNG (.png)
- Non-animated GIF (.gif)
- WEBP (.webp)
Sending Images via API
Here’s a short example on how to send an image to the model using Vellum’s Python Client SDK:
To see how to do this with other SDKs or cURL, see our API Explorer for the /execute-prompt endpoint or /execute-workflow endpoint.
Image Detail and Token Usage
When working with image models, token usage is an important factor to consider. For OpenAI vision models, the two main factors for token count are the image’s size and its detail setting.
There are three possible settings for the image detail: low, high, or auto
The low setting processes a lower resolution 512x512 version of the image. With low, the response time is faster. This setting is great when the fine details of the image are not required.
The high setting on the other hand is the high resolution mode. In this mode, the input image is tiled and a detailed segment is created from it. Token usage is calculated based on the number of these segments which correlates to the image size. High resolution allows for a more comprehensive interpretation of your image.
You can learn more about the image detail setting and OpenAI vision models on their site
Using Documents (PDFs) in the UI
Vellum also supports uploading and processing documents such as PDFs in your Prompts and Workflows. This enables you to leverage the power of LLMs for document analysis, summarization, extraction, and more.
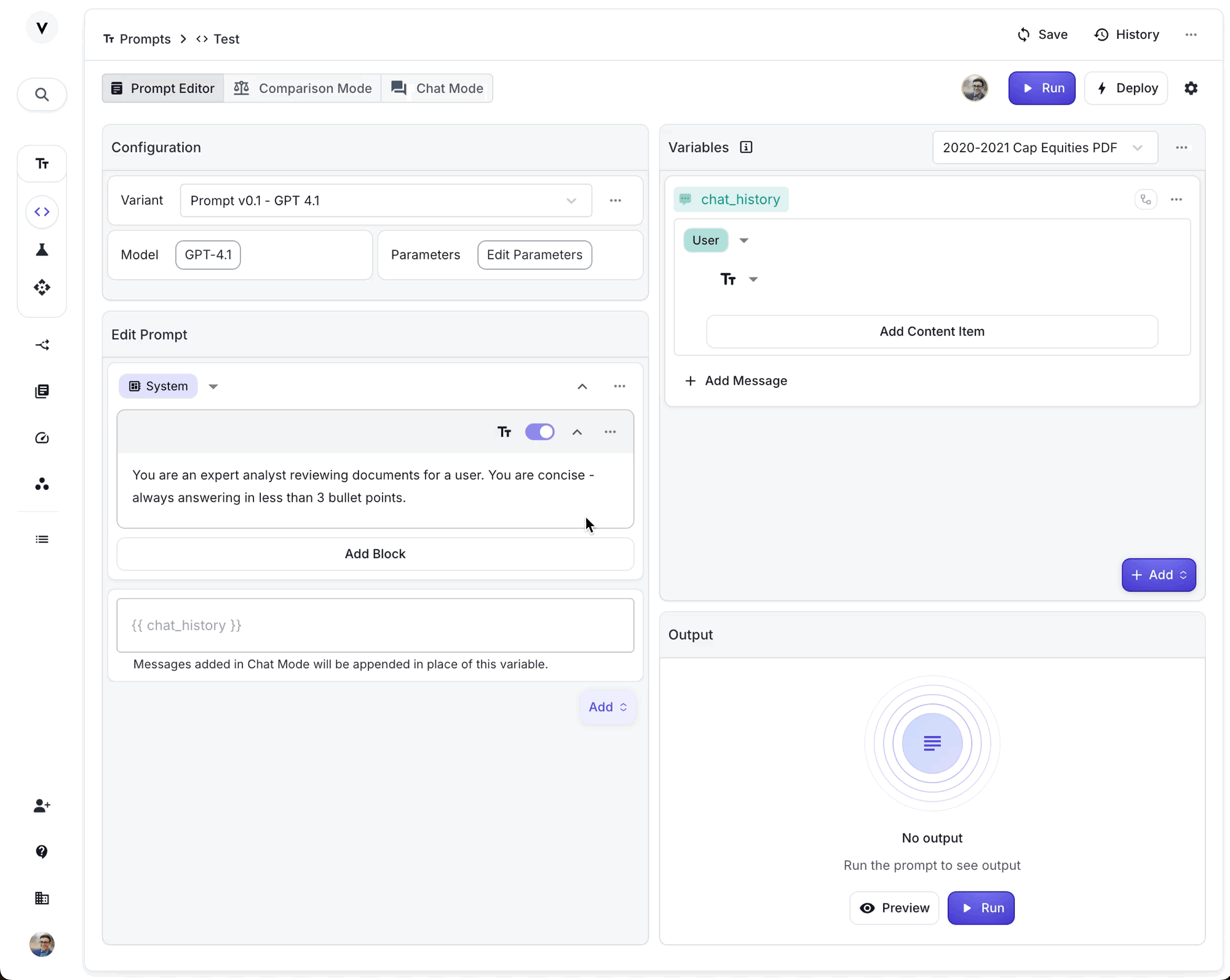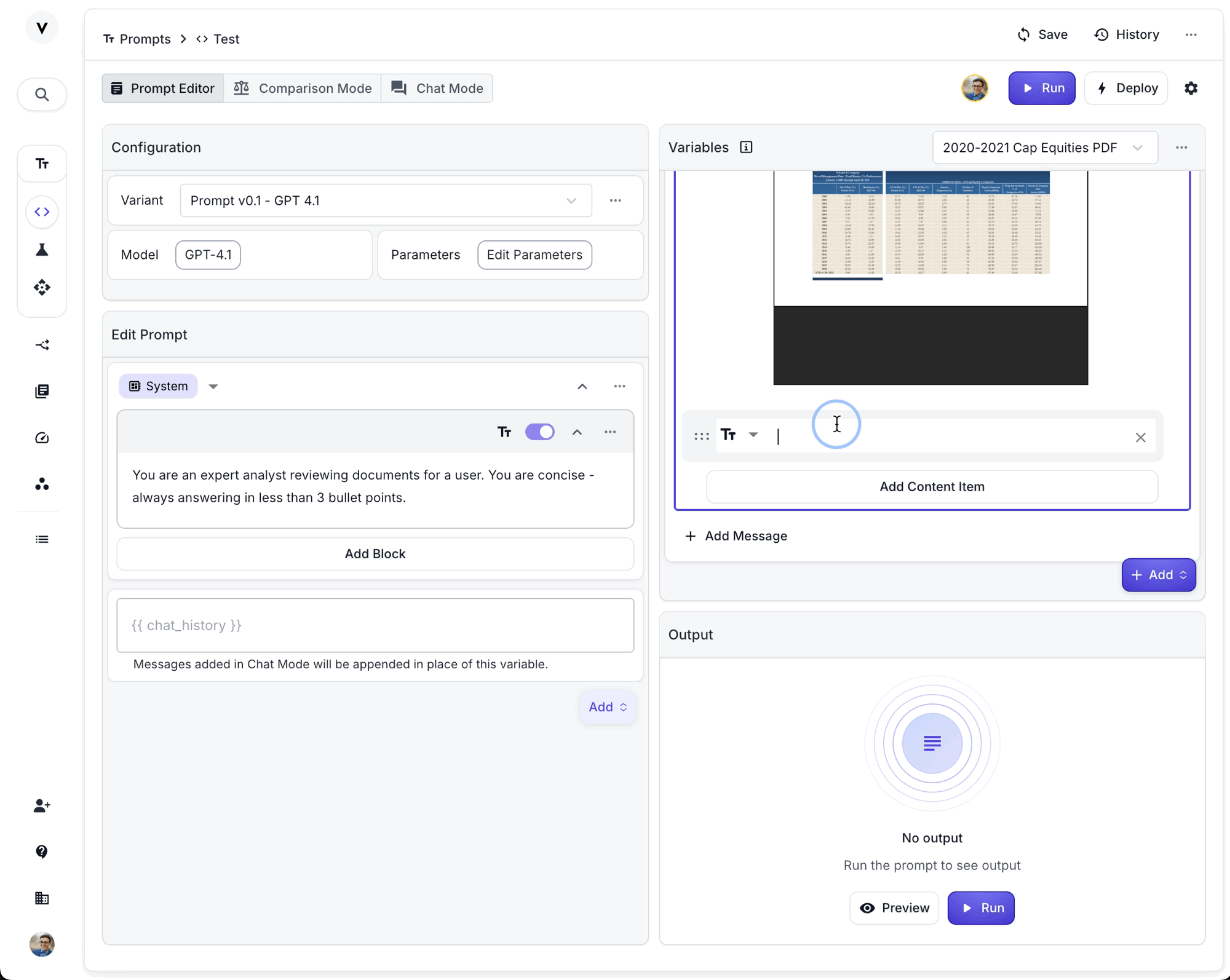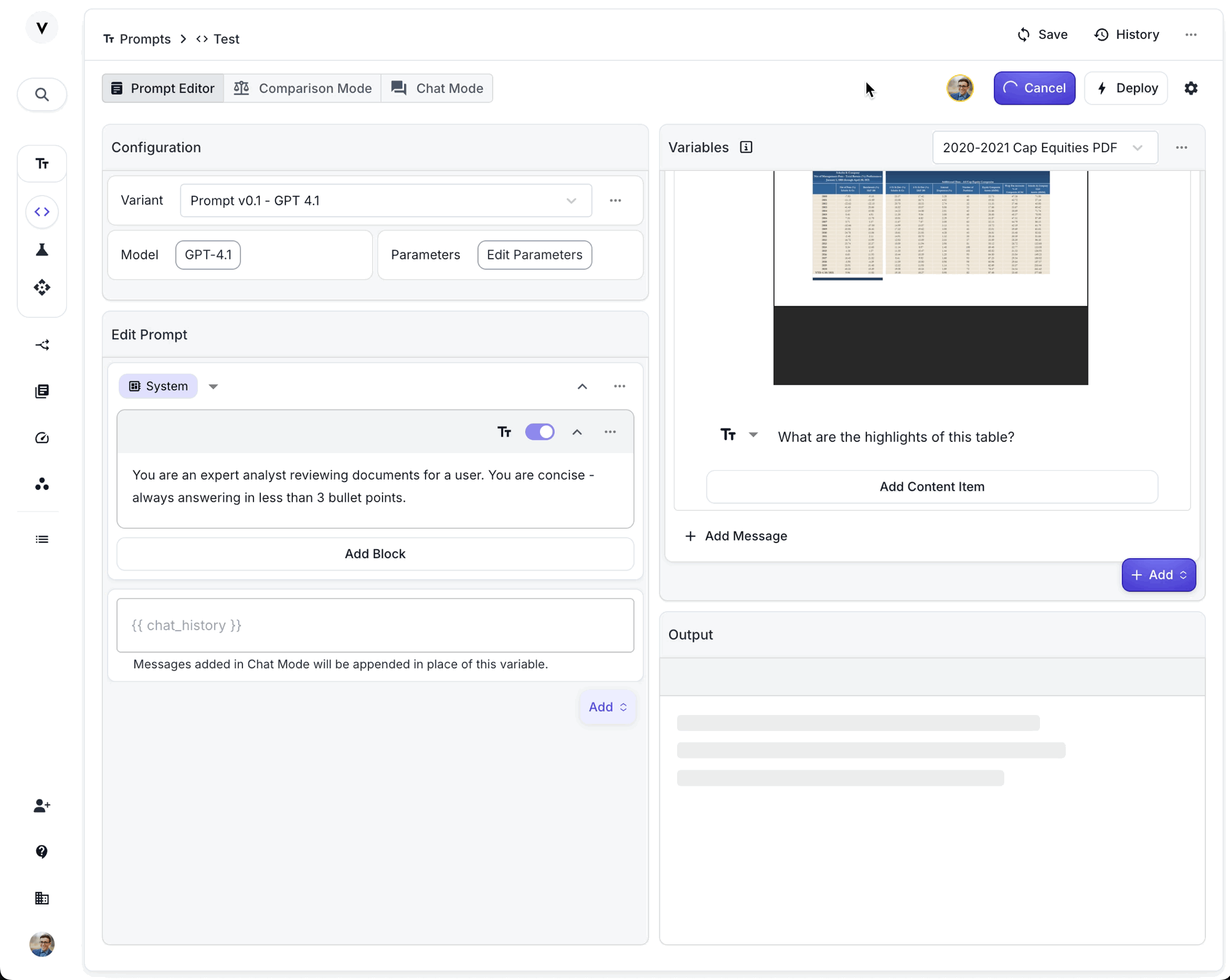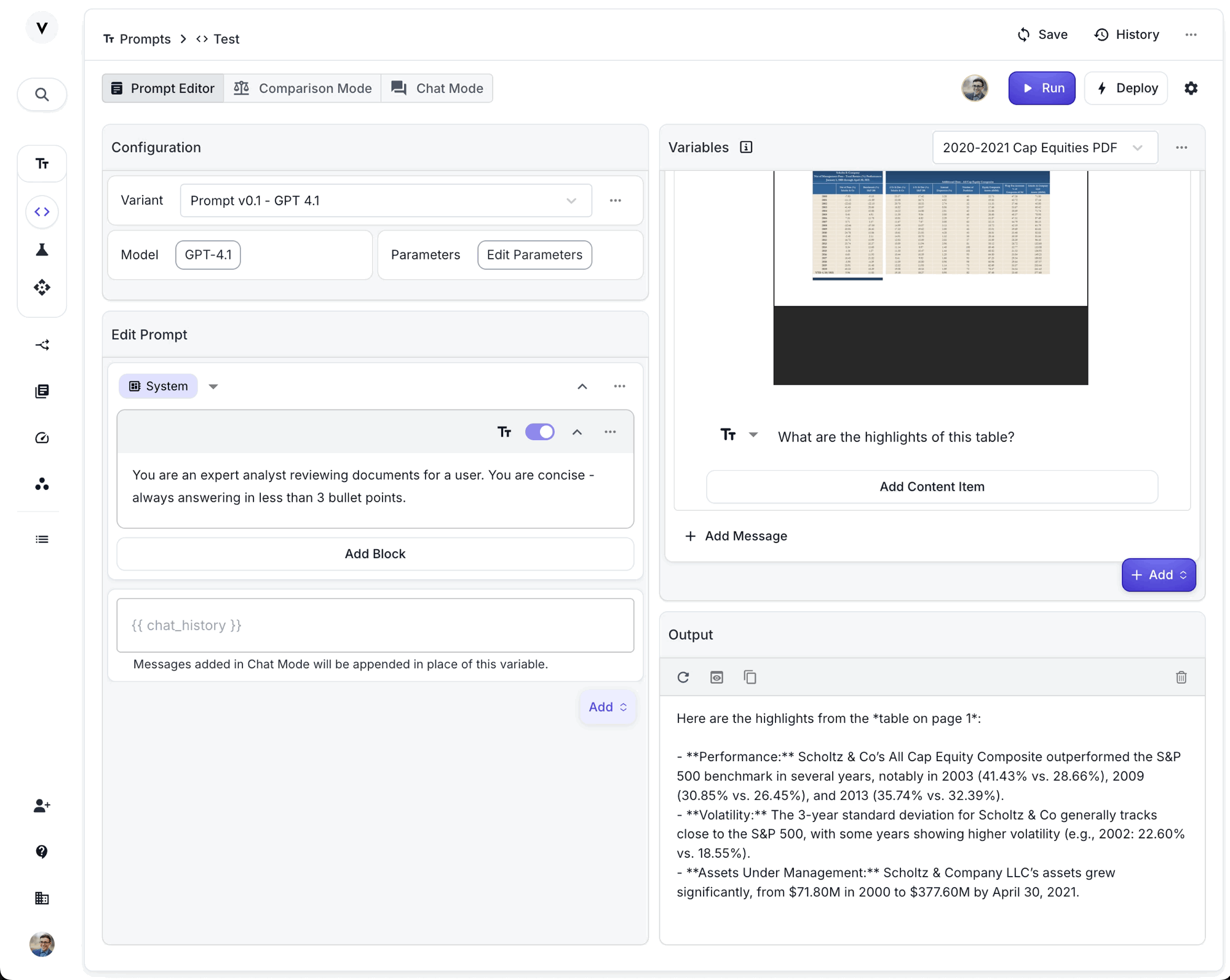
How to Add PDFs
- In the Prompt Sandbox, add a Chat History input variable by adding a new variable of type “Chat History”. This will allow you to drag and drop PDF files directly into Content Blocks.
- In the Workflow Sandbox, add a Chat History input variable by adding a new variable of type “Chat History”. This will allow you to drag and drop PDF files directly into Content Blocks.
Once the Chat History variable is set up, simply drag and drop your PDF file into a message. The document will be uploaded and available for the model to process as part of your prompt or workflow scenario.
PDFs must be publicly accessible and under 32MB in size. For best results, use standard, non-password-protected PDF files.
What Happens Next?
After uploading, the PDF will appear as an attachment in your Chat History message. You can add text alongside your document, reorder items, or remove the file as needed. The model will receive the document as part of the input and can answer questions, summarize, or extract information from it.
Sending PDFs via API
Here’s a short example on how to send a PDF to the model using Vellum’s Python Client SDK:
To see how to do this with other SDKs or cURL, see our API Explorer for the /execute-prompt endpoint or /execute-workflow endpoint.