Templating Node
The Templating Node allows you to perform custom data transformations on a set of defined inputs to create a new output. You can use this to define constants, manipulate data before feeding into a prompt, or massage a response to a format of your liking.
Templating Node Interface
The Templating Node provides a simple interface for configuring your data transformations:

When you open the Templating Node, you’ll see a detailed configuration interface where you can define your template:

Check out our Common Data Transformation Templates for some common examples.
Pro Tips
- XML Tags for LLMs: Use XML tags to help LLMs delimit where long chunks of context start and stop. This can give huge performance boosts.
- Jinja Flexibility: Remember that you can use Jinja directly in your Prompt Node Blocks as well as in Templating Nodes.
Troubleshooting Tips
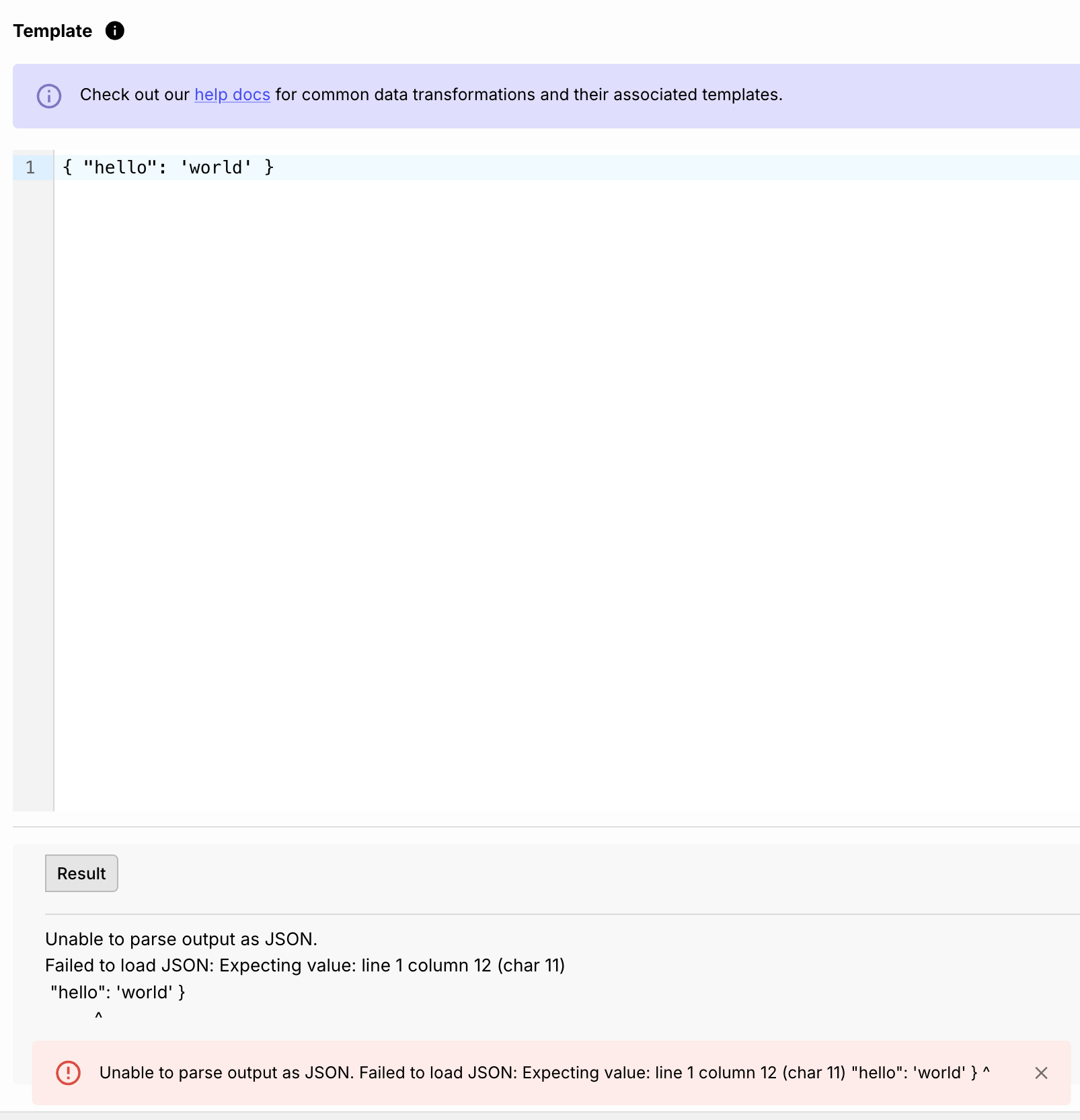
Tip: JSON Syntax
You may have a templating node that outputs JSON which seems valid, but yields the following error when you click “Test” or run your workflow:
Tips - Using Jinja
Jinja has a tendency to leave hard-to-see whitespace which can cause issues when doing equality checks in places like Metrics or Conditional Nodes.
Tip: Unexpected Whitespace
Jinja has a tendency to leave hard-to-see whitespace which can cause issues when doing equality checks in places like Metrics or Conditional Nodes.
Common Templates
The Templating Node supports Jinja2 syntax and is a flexible way of performing light-weight data transformations as part of your Workflow. Here are some common data manipulations you may want to make in a Workflow and how you define them via Templating Nodes.
String Manipulation
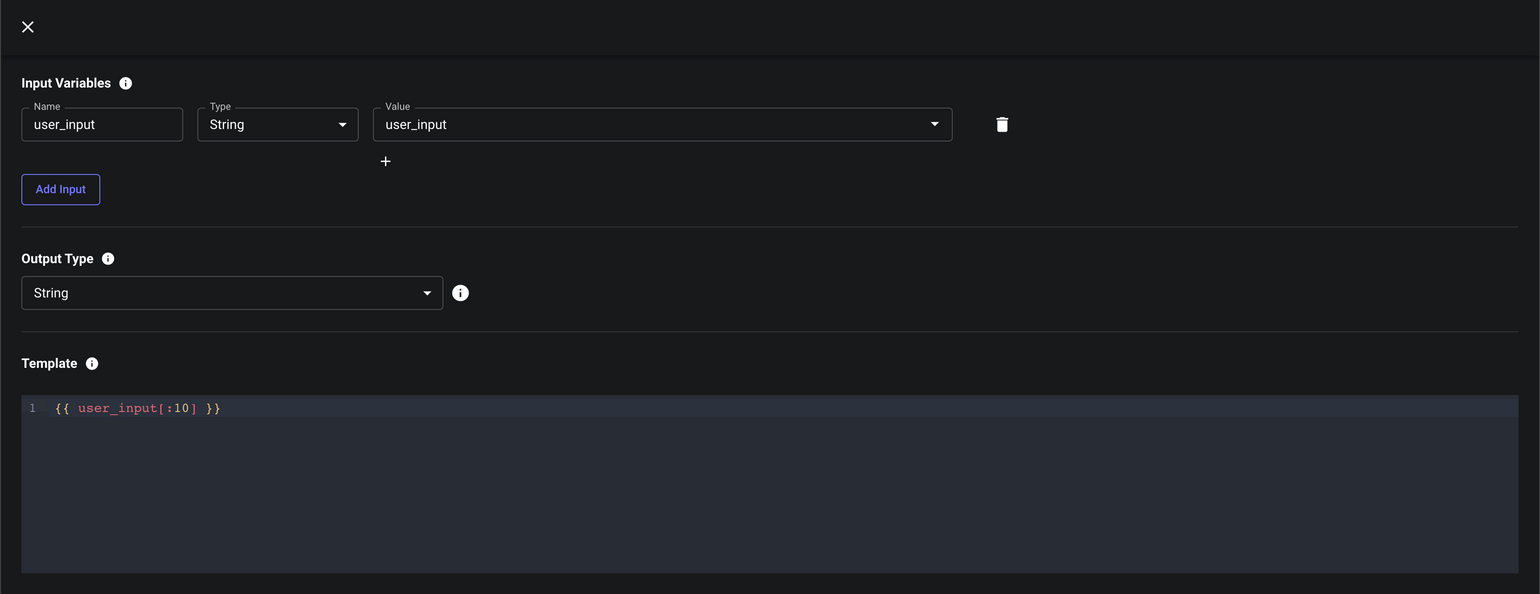
Output Only the First n Characters
Useful if you want to ensure that you’re not providing too much context to a prompt.
JSON Manipulation
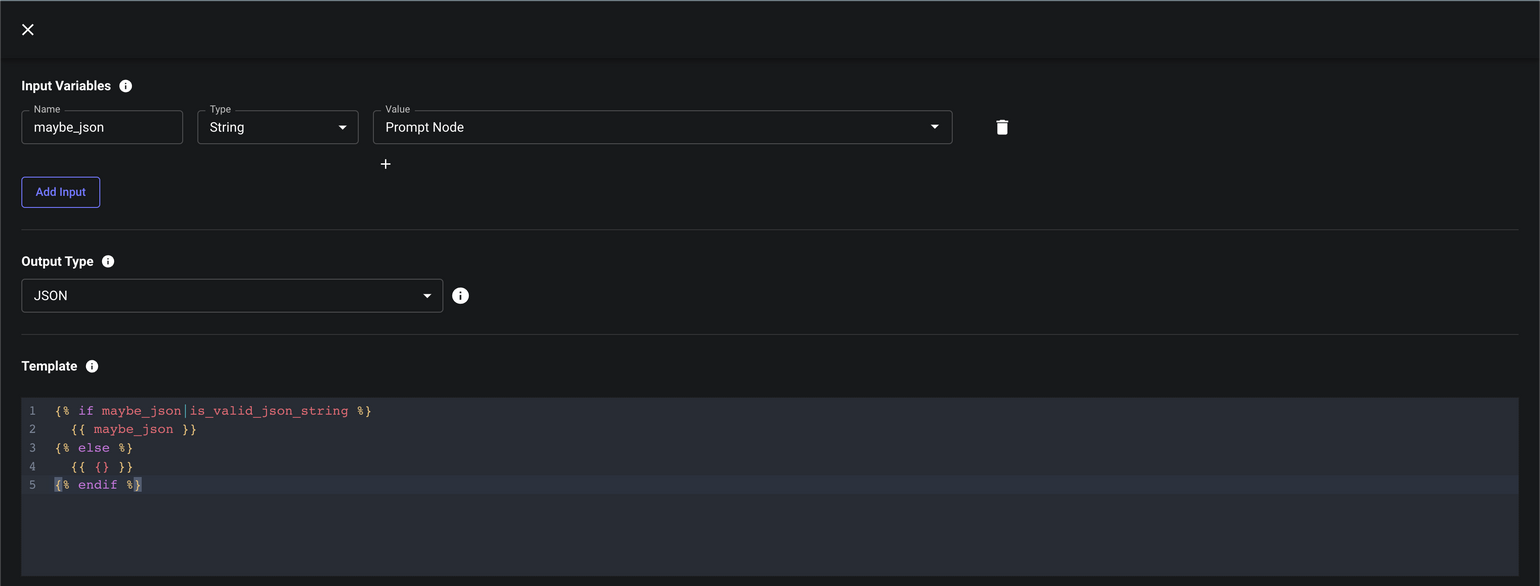
Checking LLM Output for Valid JSON
If you’re trying to extract structured JSON from unstructed text using a prompt, or if you want to use OpenAI’s function-calling functionality, it’s likely you’ll need to check whether an LLM’s response is valid JSON and if so, convert the output string as proper JSON.
You can also extract specific properties from valid JSON strings.
Here’s how to do it:
Chat History Manipulation
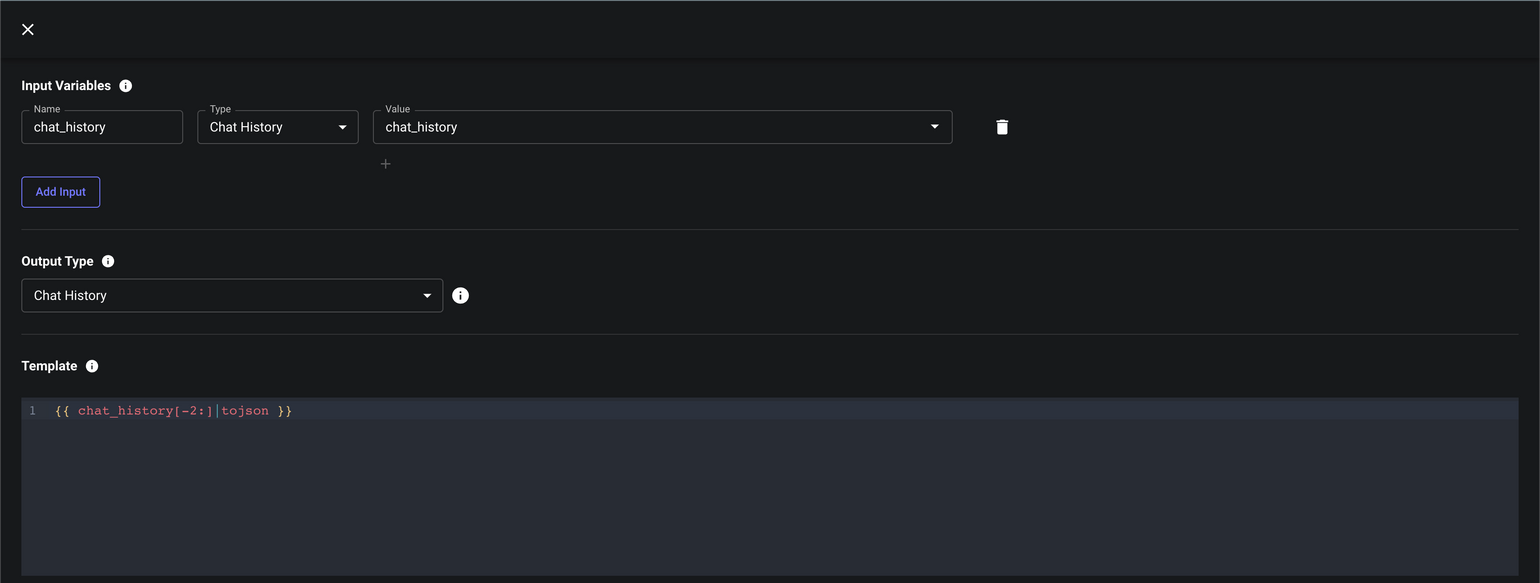
Output the Most Recent n Messages in Chat History
If you’re building a chatbot and conversations can be long-lived, you may find that your chat histories are too long to fit within the context window of a prompt.
Once simple solution is to only ever include the most recent n messages from the conversation. Here’s how you can do this:
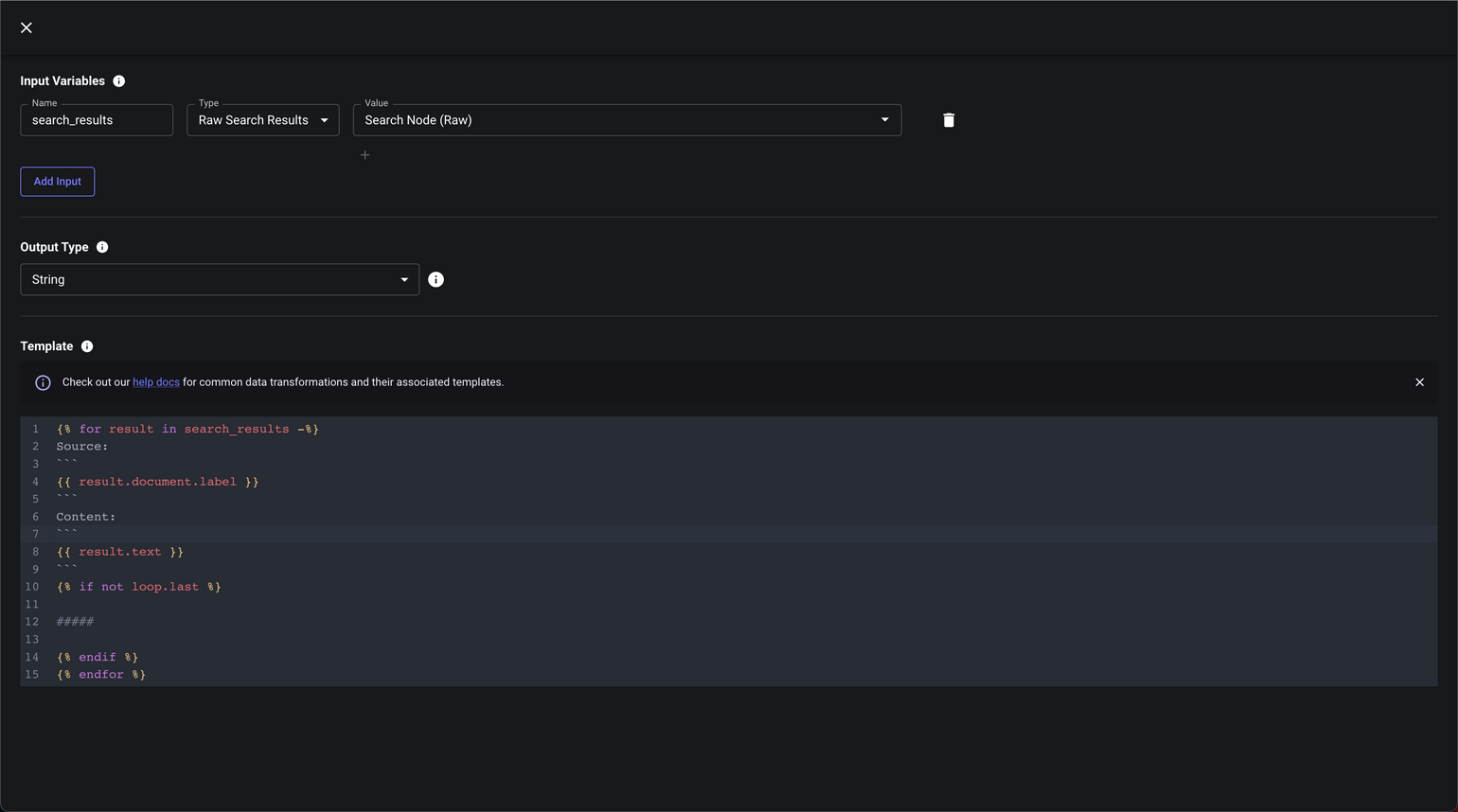
Search Result Manipulation
Citing Sources via Chunk Concatenation Customization
Search Nodes make it easy to query a vector store for text that’s semantically similar to some input. By default, the chunks of text that are returned are concatenated together into a single string using a configurable separator (e.g. \n\n#####\n\n). The flattened string can then be fed directly to Prompt Nodes as an input variable and referenced within your prompt template.
However, if you want your Prompt to cite its sources and say where it got the info it used to generate its response, then you’ll need more than just the chunk text. You need the name/id/url/etc of the document each chunk came from and you need to provide this info to your Prompt in a consumable form. This is where Templating Nodes come in.
The template below takes in the raw search results and performs custom chunk concatenation, but also pulls in info from the document associated with each chunk.