Fallback Models
Fallback Models
When building production LLM applications, it’s often beneficial to implement a fallback strategy that can dynamically select different models based on various conditions. This approach allows you to:
- Optimize for cost: Start with a cheaper, faster model and only use more expensive models when necessary
- Handle context limitations: Automatically switch to models with larger context windows when needed
- Implement error recovery: Gracefully handle model-specific errors by trying alternative models
- Balance performance and cost: Use the most appropriate model for each specific task
This tutorial demonstrates how to build a workflow that dynamically selects models and implements fallback logic when errors occur.
Implementation Overview
We’ll create a workflow that:
- Uses a Templating Node to dynamically select which model to use
- Connects the Templating Node output to a Prompt Node’s model selection
- Implements error handling with a Try adornment
- Creates a feedback loop to try a different model if the first attempt fails
Add a Prompt Node and a Templating Node
Start by adding a Prompt Node and a Templating Node to your workflow sandbox. The Templating Node will determine which model we should use in the Prompt Node.

Configure Dynamic Model Selection
Open the “Model” tab in the Prompt Node, then click the 3-dot icon next to the currently selected model. You’ll see an option for “Expressions” - this allows you to dynamically select a model. Click it to enable dynamic model selection.

Connect the Templating Node to the Model Selection
Connect the Templating Node’s output to the Prompt Node’s model field. This will allow the Templating Node to dynamically determine which model the Prompt Node should use.

Add a Try Adornment to the Prompt Node
Click anywhere on the Prompt Node to open the side panel. Navigate to the Adornments section and add a “Try” adornment. This will help us expose a new output from the Prompt Node that will let us detect errors and handle them appropriately.

Configure Conditional Routing
Navigate to the Ports tab and add a new port. Create an expression for the “If” case that checks if there was no error. If there was an error, we’ll take the “Else” path and route back to the Templating Node to select a different model.

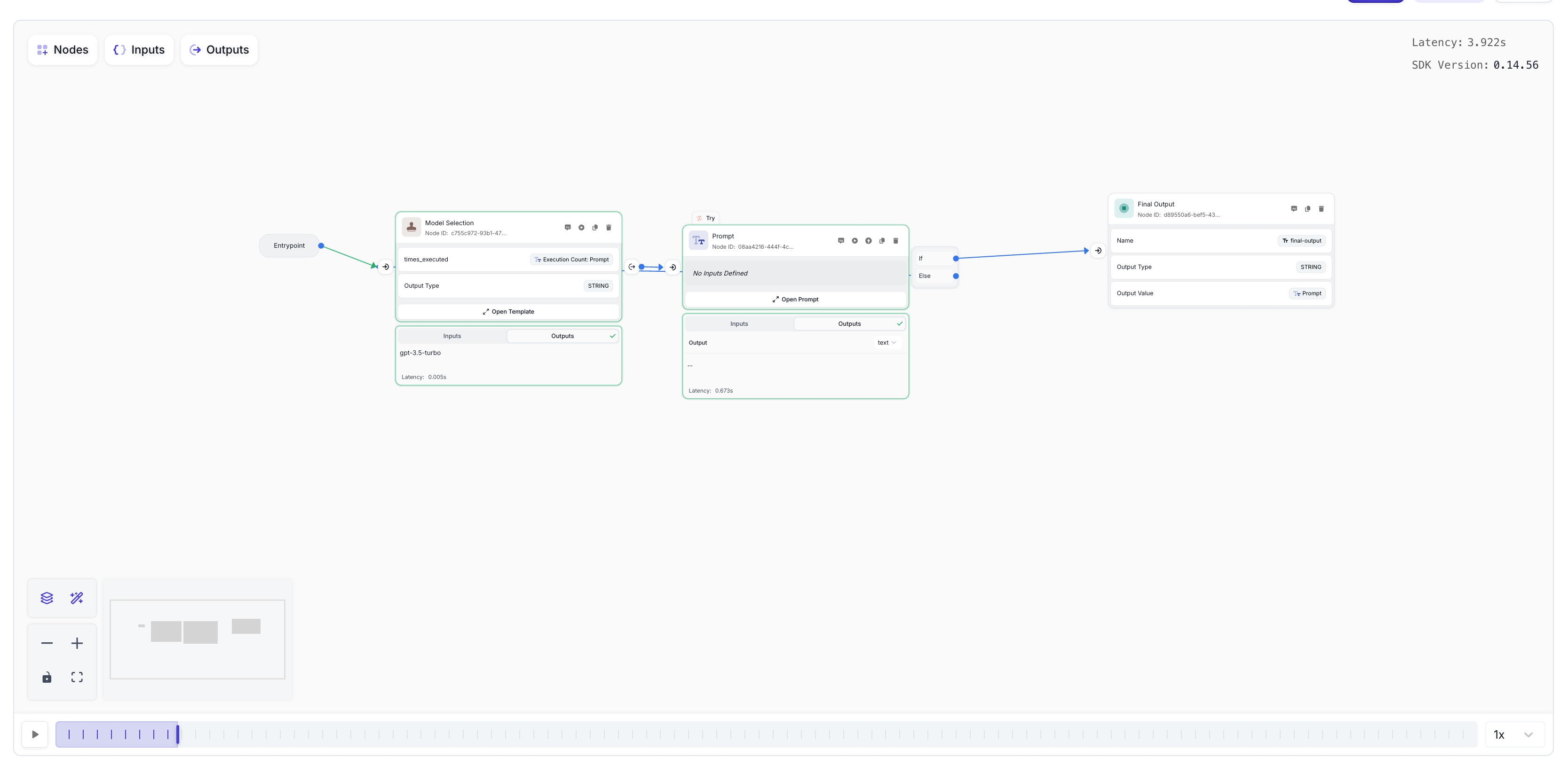
Connect the Nodes
Your canvas should now look something like this, with the Prompt Node having two output paths - one for successful execution and one for error handling:

Complete the Connections
Finish setting up your workflow by:
- Connecting the Templating Node output to the Prompt Node input
- Connecting the Entrypoint to the input of the Templating Node
- Renaming the Templating Node to “Model Selection”

Implement the Model Selection Logic
Open the Templating Node and rename the input variable to times_executed. Connect it to the Execution Count of the Prompt Node by selecting Execution Count: Prompt.
Then, paste the following Jinja template into the Template area:
This logic says:
- If our Prompt Node hasn’t run yet (execution count is 0), use
gpt-3.5-turbo(a model with a smaller context window) - If we have executed it once before (meaning there was likely an error), use
gpt-4owhich has a larger context window

Test the Workflow
To test the fallback functionality:
- Go back to your Prompt Node and delete any unused input variables
- Try pasting in a large amount of text (>16k tokens) that would exceed the context window of gpt-3.5-turbo
- Make sure your Final Output Node has its output value connected to the Prompt Node’s output
- Run the workflow

Additional Use Cases
This fallback model architecture can be extended for various scenarios:
Cost Optimization
Start with cheaper models for simple tasks, and only escalate to more expensive models when necessary.
Error Recovery
Handle various types of model-specific errors (rate limits, timeouts, etc.) by trying alternative models.
Progressive Enhancement
Begin with faster models for quick responses, then use more capable models only when the initial response doesn’t meet quality thresholds.
Context Window Management
Automatically switch to models with larger context windows when content exceeds the limits of smaller models.
Customization Options
You can customize this architecture in several ways:
- Multiple Fallback Levels: Add more conditions to try several models in sequence
- Error-Specific Handling: Check the specific error type and choose different fallback models accordingly
- Quality-Based Routing: Add a Guardrail Node to evaluate the quality of responses and trigger fallbacks for low-quality outputs
- Timeout Management: Implement timeouts to fall back to faster models when response time is critical
By implementing dynamic model selection with fallback logic, you can build more resilient, cost-effective, and performant LLM applications that gracefully handle errors and optimize for different requirements.